
公開したページがGoogleに出てこない。Search Consoleでは「クロール済み - インデックス未登録」や「検出 - インデックス未登録」と表示される。こうした状態が続くと、記事の質に問題があるのか、技術設定で止まっているのか判断しにくいものです。
Googleにインデックスされない原因は、noindexやrobots.txtの設定ミスだけではありません。内部リンクの弱さ、サイトマップの不備、サーバー応答、重複シグナル、レンダリング上の問題など、切り分けるべき論点は複数あります。この記事では、2026年の最新情報を踏まえながら、まず確認方法を整理し、そのうえで原因別の対策を実務目線でわかりやすく解説します。

この記事でわかること
まずは現状把握から!ページのインデックス状況を確認する2つの方法
ページがGoogleにインデックスされないときは、いきなり原因を推測しないことが大切です。実際の運用でも、技術設定のミスだと思って調べたら単なる未クロールだった、あるいは品質の問題だと思っていたら noindex が残っていた、というズレは珍しくありません。まずは「本当に未登録なのか」「どの単位で未登録なのか」を確認します。
簡易確認には検索結果を使う方法があり、詳細な切り分けには Search Console が向いています。両方を使い分けると、調査の無駄が減ります。
方法1:検索コマンド「site:」で簡易チェック
使い方
Google検索で site:example.com のように入力すると、そのドメイン配下で検索結果に表示されるURLを確認できます。特定ページだけを見たいなら、site:https://example.com/sample-page/ のように完全URLに近い形で調べます。
わかること
この方法の利点は、ログイン不要でその場ですぐ確認できる点です。公開したページが検索結果に現れるか、ドメイン全体でどのページが出ているかを大まかに把握できます。記事公開後の初期チェックとしては十分実用的です。
注意点
ただし、site: は厳密な管理ツールではありません。表示件数は正確なインデックス総数を示すものではなく、結果の並び順も管理目的には向いていません。つまり、「出ていれば参考になるが、出ないから即未登録と断定はしない」という使い方が基本です。特にページ単位の原因調査には次の方法が欠かせません。
方法2:Google Search Consoleで詳細なステータスを確認
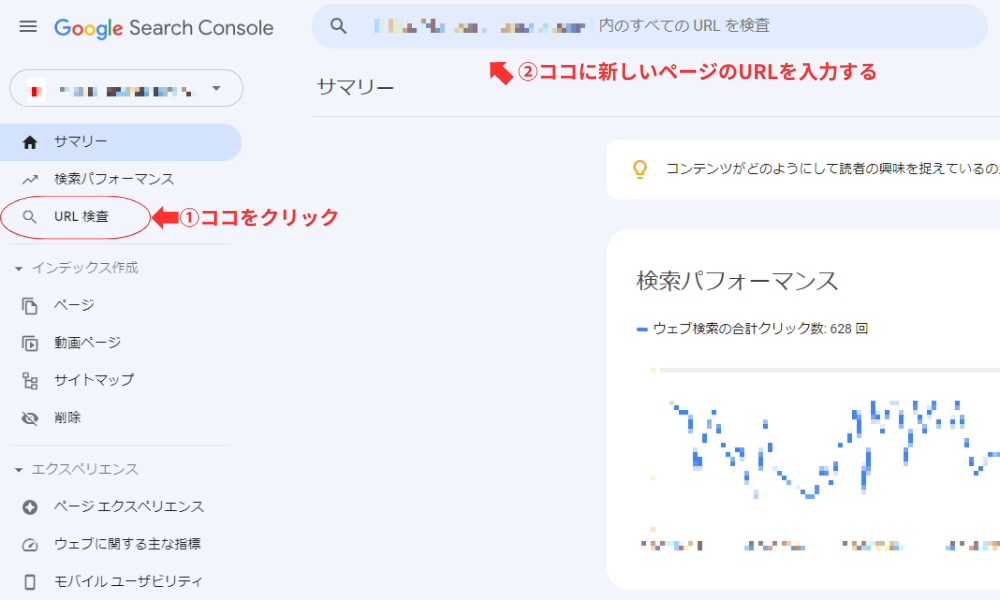
URL検査で見る
より正確に確認するなら、Google Search Console のURL検査ツールを使います。対象URLを入力すると、Googleに登録されているか、最後にクロールされたか、取得時に問題がなかったかを確認できます。必要に応じて、Googlebot が取得したHTMLも見られるため、意図しない noindex やレンダリング不備の発見に役立ちます。
レポートで全体を見る
単発のURL確認だけでなく、ページのインデックス登録レポートも重要です。ここでは「検出 – インデックス未登録」「クロール済み – インデックス未登録」などの状態をまとめて確認できます。サイト全体で同じ症状が広がっているのか、一部URLだけの問題なのかを切り分けやすくなります。
実務上の見方
Search Consoleを使ってみると、未登録という結果だけでなく、その前段階のヒントが多く出ているとわかります。noindex の抽出、クロール状況、登録可否の傾向が見えるため、次に確認すべき論点を絞れます。単に「インデックスされていない」で止まらず、クロールの問題なのか、登録判断の問題なのかを見分ける入口として使うのが正攻法です。
【重要】インデックスされない原因は2つのステージに大別される
原因を追うときは、「なぜ未登録なのか」を一つの箱で考えないことが大切です。Search Consoleで未登録を確認したあと、次に見るべき論点は大きく2つしかありません。GoogleがそのURLに十分アクセスできていないのか、それともアクセス後に登録しない判断をしているのかです。この切り分けができると、確認すべき設定と修正の順番がはっきりします。
Google検索の仕組み:クロール → インデックス → 表示
まず起きるのは「発見と取得」
Google検索は、見つけたURLに自動でアクセスし、ページのテキストや画像、動画などを取得するところから始まります。これがクロールです。既存ページのリンク、サイトマップ、外部サイトからのリンクなどが発見の入口になります。
ただし、見つけたURLをすべて同じ速度で見に来るわけではありません。サーバーが不安定だったり、応答が遅かったりすると、Googlebotはサイトに負荷をかけすぎないよう取得を抑えます。HTTP 200で安定して返せることは、検索以前の技術条件です。
次に行われるのが「内容の理解」
クロール後は、ページの内容を解析して、何のページなのかを理解する段階に入ります。ここで見られるのは本文だけではありません。title、alt属性、主要な見出し、画像や動画、メタデータ、JavaScriptで描画された内容なども含まれます。
実際に使ってみると、ブラウザでは見えているのにGoogleには伝わりにくいページがあります。特に、重要な本文がスクリプト依存で遅れて表示される構成や、ログインしないと中身が見えないページは注意が必要です。
最後に「検索結果へ出すか」が決まる
インデックスは、検索結果への出場権に近い段階です。登録された後も、検索語句との関連性や品質評価によって表示有無や順位は変わります。つまり、未表示の原因は常にインデックス不足とは限りませんが、未登録なら検索結果に出る土台がありません。
あなたの問題はどっち?「クロール問題」と「インデックス問題」
クロール問題とは
クロール問題は、GoogleがURLを見つけにくい、または見つけても取りに行けない状態です。よくある原因は、robots.txtによる遮断、サーバーエラー、リンク不足、複雑な導線、ログイン必須の設計です。公式サイトでも、他サイトからリンクされていないことや、クロール時のエラー、設計上の問題は見落としの要因として案内されています。
Search Consoleで「検出 – インデックス未登録」が多い場合は、発見はされていても取得や優先順位に課題があるケースを疑います。
インデックス問題とは
一方のインデックス問題は、クロールはされたが登録されない状態です。noindex、canonical、重複判定、薄い内容、独自性の乏しさ、メタデータの不整合が代表例です。「クロール済み – インデックス未登録」が続くなら、技術よりページ自体の評価軸を見直す段階に入っています。
ここで重要なのは、URLが取得された事実だけで安心しないことです。Googleは処理したページを必ず登録するわけではありません。内容が似通っているページ群では、代表URLだけが正規ページとして選ばれることもあります。
切り分けの実務ポイント
迷ったら、URL検査ツールの結果を次の順で読みます。まずクロール可否、次にHTTPステータス、続いて noindex や canonical、最後にページ内容です。この順番で確認すると、設定ミスと品質課題が混ざりにくくなります。
筆者の見立てでも、インデックスされない問題は「設定を直すべき案件」と「ページを作り直すべき案件」で対応がまったく変わります。先にステージを誤認すると、登録リクエストを何度送っても前に進みません。まずはクロールか、インデックスか。この二分で整理することが最短ルートです。
ステージ1:Googleにクロールされない原因と対策【技術的な問題】
ここからは、Googlebot がそもそもページに到達できていないケースを扱います。Search Console で「検出 - インデックス未登録」「クロール済み - インデックス未登録」と似た表示が並ぶことがありますが、対処は同じではありません。前者は発見や取得の段階で止まりやすく、後者は読んだ後の評価段階で止まります。
クロール問題の特徴は、ページの中身を直しても動かないことです。まずは Googlebot がアクセスできる状態か、サーバーが安定して応答しているか、リンクで辿れる構造かを点検します。検索流入の改善策として品質向上を急ぐ前に、入口の詰まりを解消するほうが早い場面が少なくありません。
原因1:robots.txtによるクロールのブロック
robots.txt は、クローラーに対して「このパスには入らないでほしい」と伝えるためのファイルです。設計意図があって設定しているなら問題ありませんが、公開後もテスト用の記述が残っていたり、ディレクトリ単位で広く遮断していたりすると、インデックスさせたいページまで巻き込まれます。
起きやすい設定ミス
実務で多いのは、管理画面や検証環境を止めるつもりで書いたルールが、本番のコンテンツ領域にも当たっているケースです。とくに `/blog/` や `/lp/` のようなディレクトリ単位の指定は影響範囲が広く、気づかないまま新規ページを長く止めてしまいます。
robots.txt はルートに置かれた 1 ファイルで動作します。つまり、サイト全体やサブディレクトリ全体に影響しやすい仕組みです。しかも Googlebot はクロール前に robots.txt を見に行くため、ここで止まると noindex のようなページ内タグすら読まれません。
確認する場所と見方
まず https://対象ドメイン/robots.txt をブラウザで開き、該当 URL に関わる Disallow がないか確認します。Search Console のページのインデックス登録レポートや URL 検査ツールでも、robots.txt による制限は把握できます。公式ヘルプでも、検索に出したい URL がブロックされている場合は設定見直しが必要と案内されています。
注意したいのは、robots.txt は「検索結果に絶対に出さない」ための仕組みではない点です。他サイトからリンクされていれば、URL だけが検索結果に現れることがあります。検索結果から確実に除外したいページなら、noindex や認証制限を使うのが筋です。
対処の基本
対処は単純で、不要な Disallow を削るか、対象パスを見直します。修正後は robots.txt が正しく配信されているかを確認し、必要に応じて URL 検査で再クロールを促します。CSS や JavaScript を広く遮断している場合も見直し対象です。表示に必要なリソースを止めると、Google がページを適切に把握しにくくなります。
原因2:サイトの技術的な問題(サーバーエラー、低速表示)
クロールされない理由が、ページではなくホスト側の不安定さにあることもあります。Google はサイトに負荷をかけすぎないようクロール速度を調整します。サーバーが 500 系エラー、503、接続タイムアウト、DNS エラーを返す状態では、Googlebot は取得頻度を落とします。
サーバー応答が不安定なときの影響
このとき厄介なのは、1ページだけの問題に見えにくいことです。特定 URL の登録が遅いように見えても、実際はホスト全体でクロールが絞られている場合があります。公式情報でも、サーバーがクロール要求に応答できないと検出したときは、Googlebot がクロールを縮小すると説明されています。
一時的な高負荷、メモリ不足、CDN 設定ミス、WAF やファイアウォールによる遮断でも同じ症状が出ます。実際に使ってみると、ブラウザではたまに表示できるのに、クローラーには断続的に失敗を返しているケースがあり、監視を入れるまで見落としやすいものです。
速度より先に見るべきこと
表示速度の話になると Lighthouse や Core Web Vitals の点数に目が向きがちですが、クロール観点ではまずHTTP ステータスと応答安定性を見ます。200 を返していても、毎回のレスポンスが極端に重い、HTML の生成が遅い、レンダリングに必要なリソース取得で失敗が多い、といった状態では巡回効率が落ちます。
確認では次の順が実務的です。
- Search Console のクロールの統計情報でホストの可用性や取得失敗の傾向を見る
- サーバーログで Googlebot のアクセス有無、応答コード、応答時間を確認する
- URL 検査で取得結果とレンダリング状態を確かめる
- PageSpeed Insights で重い要素を洗い出す
改善の着眼点
改善策は、画像最適化より先にインフラと配信の安定化が優先です。5xx の解消、タイムアウト削減、キャッシュ調整、不要なリダイレクト連鎖の解消、ボットを誤検知するセキュリティ設定の見直しが優先です。ログイン必須の状態や地域制限で Googlebot が弾かれていないかも確認してください。クロールは「読ませる前提」が整って初めて進みます。
原因3:サイト構造が複雑で発見されにくい
Google はリンクを辿って新しいページを見つけます。つまり、URL が存在していても、サイト内のどこからも辿れないページは発見が遅れます。大規模サイトや長く運営しているサイトほど、構造のゆがみが原因になりやすい領域です。
発見されにくいページの典型
発見されにくいのは、公開したのに一覧ページへ載っていない記事、絞り込み後にしか出ない商品ページ、JavaScript のクリックイベントだけで遷移する導線、パンくずや関連記事から孤立した詳細ページです。Google は一般に <a href=""> の形で書かれた標準リンクを認識しやすく、スクリプト依存の遷移は不安定になります。
検索ボックス経由でしか辿れないページも要注意です。ユーザーは見つけられても、Googlebot は通常、サイト内検索フォームに任意の語を入れて巡回しません。EC サイトで商品詳細がカテゴリ一覧から辿れない構造だと、在庫ページや派生商品が長く未発見のまま残ることがあります。
構造改善の考え方
改善では、URL を増やす前に導線を減らします。重要ページまでのクリック階層を浅くし、カテゴリ、一覧、詳細の関係を明確にします。URL 設計も大切ですが、Google は URL の見た目だけで構造を理解するわけではありません。実際には、どのページから何本リンクされているかのほうが効きます。
直すべき優先順位
優先順位は次の通りです。第一に、重要ページへ通常の HTML リンクで到達できること。第二に、モバイル版でも同じ導線を確保すること。第三に、孤立 URL を作らないことです。記事ページならカテゴリ一覧と関連記事、商品ページならカテゴリと関連商品、サービスページなら上位ページとFAQから相互に繋ぐ形が安定します。構造が整理されると、クロール効率だけでなく更新検知も早まります。
原因4:新規ドメインや被リンク不足で重要度が低い
技術設定に問題がなくても、公開直後のサイトや小規模サイトでは、Google が存在に気づくまで時間がかかることがあります。Google は自動的に新しいサイトを探しますが、すべてを同じ速度では見つけません。公式案内でも、新しいサイトや変更に気づくまで数週間かかる場合があるとされています。
新規サイトで起こること
立ち上げ初期は、内部リンクの母数が少なく、外部からの言及もほぼないため、発見の手がかり自体が少ない状態です。この段階で「品質が悪いからクロールされない」と決めつけるのは早計です。まずは存在を伝える経路を増やす必要があります。
被リンクの役割を誤解しない
被リンクは順位要因の話として語られがちですが、クロールの入口としても機能します。外部サイトから自然にリンクされると、そのリンク先 URL が見つかるきっかけになります。ただし、金銭で獲得するリンクや関連性の薄いリンクは避けるべきです。検索スパムの問題に発展しうるためです。
現実的な打ち手
新規ドメインで優先したいのは、サイトマップ送信、主要ページへの内部リンク集中、プロフィールページや会社情報など信頼確認に使われやすい固定ページの整備です。加えて、業界団体、取引先、登壇資料、プレス掲載、関連メディアなど、文脈の合う場所から自然に参照される導線を作ると発見性が上がります。
ここで焦って URL を大量公開しても、全件がすぐに巡回されるとは限りません。最初は重要ページを絞り、リンクで辿れる状態を作り、サーバーが安定して応答することを優先してください。新しいサイトほど、量より発見しやすさの設計が効きます。
ステージ2:クロール済みでもインデックスされない原因と対策【品質の問題】
クロールまでは進んでいるのに Google に登録されない場合、原因は技術的な到達性ではなく、ページ側のシグナルにあることが多いです。実務では「見つかっているのに採用されない」状態とも言えます。Search Console で見ると、URL 検査ではクロール済みでも、ページのインデックス登録レポートでは除外扱いになっているケースです。
この段階では、単に待てば解決するとは限りません。noindex や canonical のように明示的な指示が出ている場合もあれば、ページ同士が似すぎて代表URLだけが選ばれている場合もあります。さらに、内容が薄い、独自性が乏しい、需要に対して情報価値が低いと判断されると、クロールされた後でも登録されないことがあります。
原因5:noindexタグ・ヘッダーによる意図的な除外
noindex は「登録しないでほしい」という明示的な指示です
noindex は、検索結果にそのページを表示しないよう伝える設定です。HTML の meta タグでも、HTTP レスポンスヘッダーの X-Robots-Tag でも指定できます。Googlebot がページをクロールしてこの指示を確認すると、そのページは検索結果から外れます。これは不具合ではなく、設定通りの動作です。
よくあるのは、公開前の確認用ページに noindex を付けたまま本番公開してしまうケースです。CMS のテンプレート、SEO プラグイン、開発環境の設定引き継ぎで混入することもあります。HTML だけ見て問題なしと判断し、実際にはヘッダー側で noindex が返っている例も少なくありません。
見落としやすい確認ポイント
確認はページソースと HTTP ヘッダーの両方で行います。HTML の head 内に <meta name="robots" content="noindex"> や <meta name="googlebot" content="noindex"> がないかを見てください。加えて、PDF や画像、HTML 以外のファイルでは X-Robots-Tag が使われるため、ブラウザの開発者ツールやヘッダーチェッカーでレスポンスヘッダーも確認します。
実際に使ってみると、WordPress では次のような場所で noindex が入りやすいです。
- 管理画面の検索エンジン設定
- SEO プラグインの投稿単位設定
- 固定ページやカスタム投稿のテンプレート
- ステージング環境からのテーマ流用
- サーバー側のヘッダー設定
robots.txt と併用すると確認できないことがある
注意したいのは、robots.txt でクロールを止めたまま noindex を指定しても、Google がその noindex を読めない点です。noindex はクロールされて初めて認識されます。つまり、検索結果から外したいページなのに robots.txt で先に遮断してしまうと、期待通りに処理されないことがあります。
不要ページを長期的に検索結果へ出したくないなら、Googlebot がアクセスできる状態で noindex を返す設計が基本です。逆に、そもそもクロールもさせたくない静的資産や無限生成URLは robots.txt を使う場面です。目的が違います。
対処の進め方
意図しない noindex が見つかったら、設定を外したうえで URL 検査ツールから再クロールを依頼します。重要ページなら内部リンクやサイトマップにも載せて、再評価されやすい状態を作ってください。修正後もしばらく古い状態が Search Console に残ることはありますが、クロールが更新されれば反映されます。
原因6:canonicalタグによるURLの正規化
canonical は代表URLを示すための指定です
canonical タグは、似た内容のページ群のうち、どの URL を代表として扱ってほしいかを示す設定です。検索結果に出したい URL を集約する目的では有効ですが、誤って使うと本来表示したいページが代替版として扱われ、インデックスされません。
たとえば、記事ページAに対して別URLのページBを canonical で指定している場合、Google はAではなくBを代表URLとして採用することがあります。その結果、Aはクロールされても検索結果には出ず、「重複しています。ユーザーにより、正規ページとして選択されていません」や類似の扱いになることがあります。
Google が別の正規URLを選ぶこともある
実務で厄介なのは、canonical が絶対命令ではない点です。サイト側が希望を示しても、Google は内容の近さ、HTTPS、リダイレクト、サイトマップ掲載、内部リンクなど複数の要素を見て別URLを正規とみなすことがあります。
そのため、「canonical を正しく書いたのに意図通りにならない」という事態が起こります。こういう場合はタグ単体ではなく、サイト全体の整合性を見直す必要があります。内部リンクはAを指しているのに canonical はB、サイトマップにはCが載っている、という不一致は典型的な失敗です。
誤設定が起きやすい場面
特に注意したいのは、パラメータ付きURL、末尾スラッシュ違い、HTTP と HTTPS の混在、www の有無、一覧ページの並び替えや絞り込みページ、複製されたLPです。CMS やプラグインが自動出力した canonical が、意図せず上位カテゴリやトップページを指していることもあります。
また、クロスドメイン canonical にも注意が必要です。別ドメインを正規URLにすると、そのページの評価や表示先を外部側へ寄せる形になります。シンジケーションや転載運用では便利な場面もありますが、誤設定すると自サイトのURLが残りません。
修正の考え方
基本は、検索結果に残したい URL を一つ決め、その URL にシグナルを揃えることです。具体的には、canonical、内部リンク、XML サイトマップ、リダイレクト先、hreflang、パンくずのURL表記を一致させます。URL 検査ツールでは「ユーザーが指定した正規 URL」と「Google が選択した正規 URL」を確認できるため、ズレがあればそこから原因を追えます。
原因7:コンテンツの品質が低い・独自性がない
クロールされたページが必ず登録されるわけではありません
Google はクロールしたすべてのページを必ずインデックスするわけではありません。ページに十分な価値がない、検索ユーザーの需要に対して情報が弱い、類似ページの中で優先度が低いと判断されると、登録されないことがあります。ここで問題になるのは、文字数の多さではなく、ページの目的を満たす中身があるかどうかです。
現場で確認すると、登録されにくいページには共通点があります。結論が遅い、他サイトの要約で止まっている、タイトルに対して本文が浅い、検索意図に対する答えが途中で途切れる。このあたりです。単なる言い換えや寄せ集めでは、クロール後に採用されにくくなります。
低品質と見なされやすいページの特徴
ユーザーの役に立つ本題より先に、水増しの前置きが長いページは不利です。短く答えられる内容なのに、意味の薄い一般論を何段も挟むと、必要な情報へたどり着きにくくなります。レビュー記事なのに実体験や比較観点がなく、他サイトの説明を並べ替えただけのページも同様です。
品質を落としやすい典型例を挙げると、次のようになります。
- 見出しは多いが本文が薄い
- 他ページの要約や言い換えが中心
- 検索意図への回答が冒頭にない
- 著者情報や根拠が乏しく信頼性を補えない
- 広告や補助要素が本文理解を妨げる
改善は「加筆」より「価値の再設計」が先です
品質の問題に対して、単に段落を増やすだけでは改善しません。必要なのは、そのページが誰のどんな判断を助けるのかを明確にし、それに沿って情報を組み直すことです。比較ページなら比較軸を増やす、手順ページなら失敗条件や例外対応を書く、解説ページなら誤解しやすい点を先回りして補足する。こうした再設計が効きます。
筆者として特に差が出やすいと感じるのは、一次情報への接続です。公式仕様、利用条件、画面上の挙動、公的データ、運用上の制約など、読者が判断に使える具体物を示すと、単なるまとめ記事から抜け出しやすくなります。逆に、抽象論だけを整えても差別化にはなりません。
品質改善後の扱い
大幅に作り直したページは、再クロール依頼だけでなく、関連ページから内部リンクを張り直し、タイトルと見出しも内容に合わせて調整します。改善前の弱い内容を残したまま小修正を重ねるより、不要なら統合や削除も含めて整理したほうが全体の評価管理はしやすいです。
原因8:重複コンテンツと見なされている
重複は「同じ文章」だけを指しません
重複コンテンツというとコピーを連想しがちですが、実際には主内容が非常に似ているページも含まれます。Google は似たページ群をまとめ、その中から代表となるページを選びます。残りは代替版として扱われ、クロールされてもインデックスされないことがあります。
同一サイト内では、絞り込みURL、並び替えURL、印刷用ページ、計測パラメータ付きURL、モバイル別URL、テスト環境の残存ページなどが重複源になりやすいです。EC では色違い・サイズ違いで本文がほぼ同じ商品ページ、メディアでは地域名だけ差し替えた量産記事が典型です。
ペナルティより先に「代表URLの選別」が起こります
通常の重複は、ただちにスパム扱いされる話ではありません。多くの場合は、どの URL を検索結果に出すかの選別が起こるだけです。ただし、大量生成された薄い類似ページや、コピー中心のページ群は別問題です。検索スパムの文脈に近づき、サイト全体の管理品質を疑われやすくなります。
重要なのは、重複があると評価が分散することより、Google に「どれが本命か」を迷わせる点です。内部リンク、サイトマップ、canonical、リダイレクトが揃っていないと、本来残したいページが代表に選ばれないことがあります。
実務での切り分け方
Search Console のURL検査で Google が選んだ正規URLを確認し、意図と違うなら、類似URL群を洗い出します。そのうえで、残す・統合する・リダイレクトする・canonical を付ける・noindex にする、のどれで整理するか決めます。全部を残す設計は管理コストが高く、検索側にも判断負荷を与えます。
重複整理の判断は次のように分けると進めやすいです。
- 完全に同じ役割のURLは 301 リダイレクトで統合
- 近いが残す必要があるURLは canonical で代表を示す
- 検索流入が不要な一覧や条件URLは noindex を検討
- 内部リンクとサイトマップは代表URLだけに寄せる
よくある改善例
たとえば、同じ記事が /column/slug と /blog/slug の両方で表示されているなら、片方へ統合したほうが明快です。商品一覧の並び替えURLが大量に生成されるなら、検索対象にしたい一覧だけを残し、その他は制御します。地域ページを量産している場合は、見出しだけでなく本文、事例、注意点、料金条件まで地域差を反映できるかを基準に残すかどうかを決めるべきです。
クロール済みなのにインデックスされないページの多くは、設定ミスか、代表URLの競合か、内容価値の不足に集約されます。Search Console の表示だけを見て一律に再登録を押すのではなく、そのページが「登録される前提を満たしているか」を見直すことが近道です。
インデックス登録を促進するための応用テクニック【2026年最新版】
Search Console で原因を切り分けたら、次は「見つけてもらいやすくする工夫」を積み上げます。ここで紹介する施策は、インデックス登録を保証するものではありません。ただ、Google に新規URLや更新URLの存在を伝えやすくし、発見から再クロールまでの流れを整えるうえで有効です。実際に運用してみると、設定そのものより「更新情報が正しく伝わる状態を保てているか」で差が出ます。
XMLサイトマップを送信・更新する
新規URLと更新URLを伝える
XMLサイトマップは、重要なURLをまとめて検索エンジンへ伝えるためのファイルです。新しいページを公開したのに内部リンクがまだ少ない、階層が深くて発見されにくい、といった場面で特に役立ちます。Search Console に送信しておくと、Google がいつサイトマップを取得したか、形式エラーがないかも確認できます。
公開後にやるべきなのは、単に一度送信して終わりにしないことです。新規ページを追加したらサイトマップに反映し、既存ページを大きく更新したら更新日時も正しく伝わる状態にします。
<lastmod> を活かす
更新ページがあるなら、XMLサイトマップの <lastmod> を適切に使う価値があります。これは「そのURLが最後に更新された時点」を示す要素で、既に登録されているURLの再確認を促すヒントになります。本文をほとんど変えていないのに機械的に日付だけ更新すると、かえって情報の信頼性を落としやすいです。実質的な更新があったページだけ反映させる運用が向いています。
送信時の注意点
サイトマップには、検索結果に出したいURLだけを載せます。noindexのURL、リダイレクトURL、エラーURLまで入れると、クロールの優先度が散ります。大規模サイトでは特に無駄が出やすい部分です。
また、同じ内容のサイトマップを短時間に何度も送る必要はありません。更新時に反映し、Search Console 側で取得状況を見守る進め方で十分です。公式情報でも、サイトマップはあくまで重要なヒントであり、送信したURLが即時にすべてクロールされるわけではないと案内されています。
内部リンク構造を最適化する
発見される導線を増やす
Google はリンクをたどってページを見つけます。つまり、重要なページほど、サイト内の複数箇所から自然に到達できる構造にしておく必要があります。記事公開後に一覧ページへ追加されていない、カテゴリから辿れない、関連記事にも出てこない。この状態では、URLが存在していても発見が遅れやすいです。
実務では「孤立ページ」がよく残ります。CMS上では存在していても、どこからもリンクされていないページです。最低でも1本、できればテーマ上関連するページから文脈つきでリンクします。
リンクは標準の <a href> を使う
内部リンクは、Google が解釈しやすい標準の <a href> で設置するのが基本です。JavaScriptのクリックイベントだけで遷移させる実装、hrefのない疑似リンク、検索フォーム経由でしか辿れない導線は不安定です。ユーザーには見えていても、クロールの面では弱くなります。
アンカーテキストも重要です。「こちら」「詳しく見る」だけで埋めるより、リンク先の内容が伝わる文言にしたほうが、ページ同士の関係を理解してもらいやすくなります。
モバイル版のリンク欠落に注意
モバイル版とPC版で別HTMLを使っているサイトでは、モバイル側のリンクが少なくなっていないか確認が必要です。Google はモバイル版を主に見ます。PC版では回遊できるのに、モバイル版では主要カテゴリや関連記事へのリンクが削られていると、新規ページの発見が遅れることがあります。モバイルで省略したリンクは、少なくともサイトマップで補完しておくべきです。
質の高い被リンクを獲得する
外部から見つけてもらう経路を作る
小規模サイトや新規ドメインでは、外部サイトからのリンクがほとんどないまま運用が始まることが少なくありません。この状態だと、Google がサイトの存在や重要ページを把握するまで時間がかかる場合があります。関連分野のサイト、業界団体、取引先紹介、登壇資料、プレス掲載、関連メディアなどから自然に参照される形を目指すと、発見経路を増やせます。
被リンク購入は避ける
被リンク獲得でやってはいけないのが、順位操作を目的にリンクを購入することです。Google のスパムに関するポリシーでも、金銭や見返りを伴う不自然なリンクには注意が促されています。短期的に数を増やす発想は、インデックス促進どころか評価面のリスクになりかねません。
獲得しやすい題材を作る
リンクされやすいのは、単なるサービス紹介より、他サイトが引用しやすい情報です。たとえば、業界用語の整理、一次情報を含む調査、比較表、法改正の要点整理、よくある誤解の解説などは参照されやすい傾向があります。契約してわかったのは、リンクは依頼文の巧拙より「相手が紹介する理由を持てるか」で決まりやすいということです。
被リンクは数だけで判断しません。テーマが近いサイトから、本文の流れの中で自然に張られているかを見ます。まずは紹介される価値のあるページを作り、そのうえで既存の接点がある先へ丁寧に知らせる。この順番が堅実です。
Googleにインデックスされない時によくある質問(FAQ)
検索結果に出ない理由は、設定ミスと評価上の問題が混ざりやすく、見た目だけでは判別しにくいものです。実際に使ってみると、Search Console のステータス文言をそのまま読むより、「Googleはまだ取りに来ていないのか」「取りに来たが採用しなかったのか」を分けて考えるほうが対処しやすくなります。ここでは、現場で質問が多い4点を絞って整理します。
Q1. 「検出 – インデックス未登録」はどういう意味で、どうすれば解決できますか?
意味
これは、Google が URL の存在は把握したものの、まだクロールしていない状態です。URL を見つけてはいるので、完全に未発見ではありません。ただし、取得の優先度が低い、サイト側の応答が不安定、負荷を避けるため再訪が後回しになっている、といった事情で止まることがあります。
対処
まず確認したいのは、サーバーが安定して 200 を返しているか、ログイン必須やアクセス制限がないかです。シークレットウィンドウで誰でもページを開けるかを確認してください。次に、XMLサイトマップへURLを載せ、重要ページから通常のaリンクで内部リンクを張ります。Search Console の URL 検査からリクエストするのも有効です。
Q2. noindexタグが意図せず設定されていないか確認する方法は?
確認箇所
noindex は HTML の meta タグだけでなく、HTTP レスポンスヘッダーの X-Robots-Tag でも設定できます。HTML ページは head 内を、PDF や画像などの非HTMLはレスポンスヘッダーを見ます。
実務での見方
Search Console の URL 検査ツールで、Googlebot が取得した HTML を確認するのが確実です。ソースコード上で <meta name="robots" content="noindex"> や <meta name="googlebot" content="noindex"> がないかを確認し、あわせて開発者ツールやヘッダーチェッカーで X-Robots-Tag: noindex の有無も見ます。CMSの公開設定やSEOプラグインで意図せず入ることもあるため、テンプレート単位でも点検すると漏れを防げます。
Q3. Googleに早くインデックスしてもらうためのコツはありますか?
優先する打ち手
最も直接的なのは、Search Console の URL 検査ツールから個別に登録をリクエストする方法です。ただし、何度も同じURLを送っても早くなるわけではありません。公開後すぐに連打するより、取得可能な状態を整えてから送るほうが筋が良いです。
併用したい整備
新規ページはXMLサイトマップに含め、更新日が変わったページは sitemap の更新も反映させます。加えて、トップページやカテゴリページなど、クロールされやすい重要ページから新規ページへ内部リンクを設置してください。Google公式でも、公開当日の登録を前提にせず、通常は数日以上かかるケースがあると案内されています。即時反映を期待しすぎず、取得しやすい導線を作ることが近道です。
Q4. インデックスされているのにGoogle検索結果に表示されないのはなぜですか?
よくある原因
インデックス登録は、検索結果への常時表示を保証しません。検索クエリとの関連性が弱い、同じテーマでより適したページが他にある、内容が薄く評価対象として弱い、手動による対策やセキュリティ上の問題がある、といった理由で表示機会が少ないことがあります。
確認手順
まず Search Console の検索パフォーマンスで、どのクエリに対して表示実績があるかを見ます。想定語句でインプレッションが出ていないなら、タイトルや見出し以前に、ページの主題が曖昧な可能性があります。表示回数が急に落ちた場合は、手動による対策レポートやセキュリティの問題も確認してください。「どの検索に対して候補に入っているか」まで追うことが重要です。
まとめ:原因を正しく切り分け、適切な対策を
切り分けの順番
Googleにインデックスされないときは、闇雲に修正するより、まず「クロールされていない」のか「クロール済みだが登録されない」のかを分けて考えることが近道です。Search Console のURL検査で状態を確認し、robots.txt、noindex、canonical、サーバー応答、ページ品質の順に見直すと原因を絞り込みやすくなります。
優先して直すポイント
技術面の確認
クロール不可の状態では、内容が良くても登録は進みません。ブロック設定、エラー、サイト構造、サイトマップ送信を先に整えるべきです。
品質面の確認
技術的な問題がないのに登録されない場合は、重複、独自性不足、検索意図とのズレを疑います。実際に使ってみると、ここを後回しにすると改善が長引きやすいものです。
最後に確認したいこと
公式サイトでも、新しいページの登録には時間差があると案内されています。公開直後に結論を急がず、修正後は再クロールを促し、数日から数週間の単位で状態を追ってください。原因を一つずつ外していけば、対応の優先順位は明確になります。
