robots.txtとは、検索エンジンのクローラーに対して「このサイトのどのURLをクロールしてよいか」を伝えるためのテキストファイルです。
ただし、最初に押さえたいのは、robots.txtは検索結果からページを消すための仕組みではないという点です。主な役割は、クロールの集中先を整理し、不要なURLへの巡回を抑えることにあります。
「どのページを止めるべきか」「noindexと何が違うのか」「書き方を間違えると何が起きるのか」を整理したい方は、ここからrobots.txtの実務的な使い方を確認していきましょう。

この記事でわかること
robots.txtの役割は「クロール制御」であり「非公開化」ではない
robots.txtの役割は、クローラーのアクセス先を調整することです。インデックス削除や機密保護のための設定ではありません。
検索エンジンは、サイト内のURLを見つけると、まずクロールできるかを確認します。その際に参照されるのがrobots.txtです。ここで特定のパスをDisallowしておくと、そのURL群への巡回を抑えられます。たとえば、ECサイトの絞り込みURL、並び替えURL、テスト環境由来の不要ページ、重複しやすい検索結果ページなど、検索流入に寄与しにくいURL群を整理する場面で有効です。
一方で、robots.txtでブロックしたURLが、必ず検索結果に出なくなるわけではありません。外部や内部からリンクされていれば、URLだけが検索結果に出ることがあります。つまり、robots.txtは「見せない設定」ではなく、「読みに行かせない設定」と理解するのが正確です。
実務でよくあるのは、開発環境のURLや会員向けページをrobots.txtだけで守ろうとしてしまうケースです。この使い方では不十分で、非公開にしたい情報は認証やnoindexなど別の手段で制御する必要があります。
(参照:robots.txt の概要とガイド)
SEOでrobots.txtが必要になるケース

robots.txtは、すべてのサイトで必須ではありません。効果が出やすいのは、不要URLが増えやすい中〜大規模サイトや、クロール先を整理したいサイトです。
小規模なコーポレートサイトや数十ページ規模のサービスサイトでは、robots.txtを細かく触らなくても問題ないことが多いです。逆に、URLの種類が多いサイトでは、何も制御しないまま運用すると、重要ページにクローラーが十分回らない状態が起きやすくなります。
クロールを絞ったほうがよい代表例
以下のようなURLが大量に発生するサイトでは、robots.txtの検討余地があります。
- ECで色違い・サイズ違い・並び替え条件ごとにURLが増えるサイト
- 求人サイトや不動産サイトで検索条件の組み合わせURLが大量生成されるサイト
- サイト内検索結果ページがそのまま公開されているサイト
- テスト用ディレクトリや一時公開ページが残りやすい運用体制のサイト
- PDFや画像など、検索流入の優先度が低いファイル群を整理したいサイト
こうしたURL群は、ユーザーにとって価値が低いとは限りませんが、検索エンジンに優先して見てほしいページとは限りません。重要なカテゴリページ、商品詳細、サービスページ、比較記事などにクロールを寄せたいなら、不要URLを放置しないことが大切です。
robots.txtを急いで触らなくてよいケース
一方で、次のようなサイトでは、robots.txtの最適化より先にやるべきことがある場合が多いです。
- 公開ページ数が少なく、URL構造も単純なサイト
- そもそも主要ページがインデックスされていないサイト
- 内部リンクやサイトマップの整備が不十分なサイト
- コンテンツ品質や重複整理のほうが課題として大きいサイト
当社でもテクニカルSEOの見直しでは、robots.txtの調整より先に「どのURLを評価してほしいのか」がサイト全体で揃っているかを確認することがあります。URL設計が曖昧なままブロックだけ増やしても、評価の分散は解消しにくいためです。
robots.txtとnoindexの違い
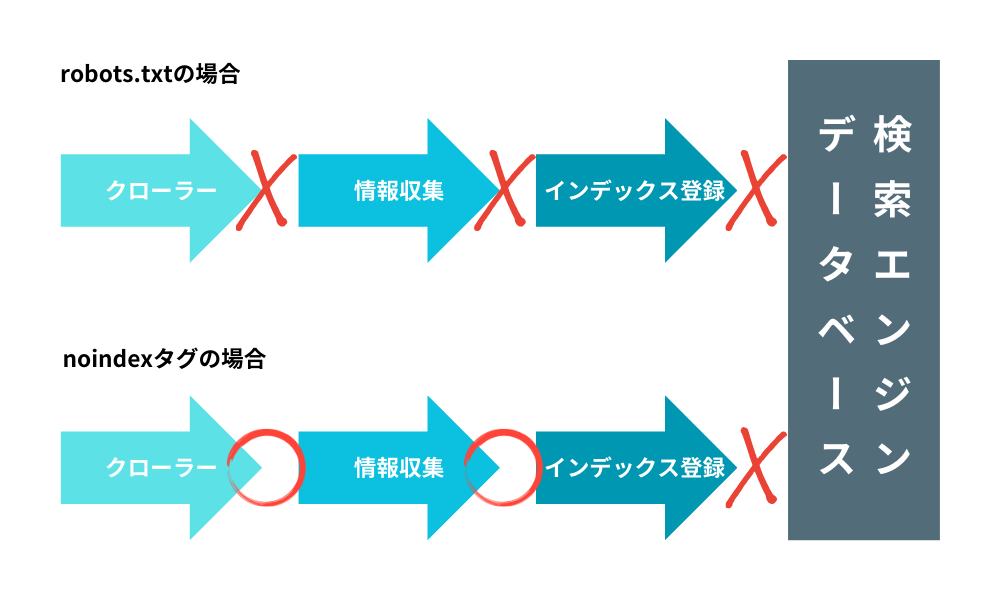
robots.txtとnoindexは似て見えますが、制御している対象が違います。robots.txtはクロール制御、noindexはインデックス制御です。
この違いを曖昧にすると、「検索結果から消したいのに消えない」「noindexを書いたのに反映されない」といったトラブルが起きます。
違いを一言で整理するとこうなる
| 項目 | robots.txt | noindex |
|---|---|---|
| 目的 | クローラーの巡回先を制御する | 検索結果に載せないようにする |
| 設置場所 | サイト直下の /robots.txt | 各ページのmetaタグまたはHTTPヘッダー |
| クローラーのアクセス | 止められる | アクセスは必要 |
| 検索結果への非表示 | 保証しない | 目的に合う |
たとえば、問い合わせ完了ページ、会員登録後だけ見せたいページ、重複ページの整理対象などは、検索結果に出したくない意図が明確です。この場合はrobots.txtではなくnoindexのほうが適しています。
両方を同時に使うと起きやすい誤解
noindexを効かせたいページをrobots.txtで先にブロックすると、クローラーがページを読めないため、noindexを確認できません。
つまり、「クロール禁止」と「noindex確認」は両立しないことがあります。検索結果から外したいページは、まずクロール可能な状態でnoindexを認識させ、その後の扱いを判断するのが基本です。
この点は現場で混同されやすく、特にCMSの一括設定で「noindex対象ディレクトリをrobots.txtでも止める」運用は事故につながりやすいです。検索結果から消したいのか、単に巡回を抑えたいのかを先に決めると判断しやすくなります。
(参照:robots メタタグ、data-nosnippet、X-Robots-Tag の仕様)
robots.txtの基本構文と書き方
robots.txtの書き方は難しくありません。最低限押さえるべきなのは、User-agent、Disallow、Allow、Sitemapの4つです。
まずは全体像を見てから、各行の意味を理解すると迷いにくくなります。
User-agent: * Disallow: Sitemap: https://www.example.com/sitemap.xml
この例は「すべてのクローラーに対して、特にクロール禁止はしていない。サイトマップはここにある」と伝える書き方です。Disallowが空欄なら、全面禁止ではありません。
User-agent
User-agentは、どのクローラーにルールを適用するかを指定する行です。
User-agent: *
「*」は全クローラー向けです。特定のクローラーだけに別ルールを当てたい場合は、そのクローラー名を指定します。たとえばGooglebot向けに個別設定を書くこともできますが、実務では全体ルールだけで足りるケースが多いです。
Disallow
Disallowは、クロールさせたくないパスを指定します。
User-agent: * Disallow: /search/
この例では、/search/配下をクロール対象から外します。サイト内検索結果ページや、不要な条件URLをまとめて抑えたいときに使いやすい書き方です。
サイト全体を止めるなら以下です。
User-agent: * Disallow: /
ただし、これは本番サイトで誤って入れると致命的です。開発環境の設定をそのまま本番へ持ち込む事故は珍しくありません。公開前チェックでは、robots.txtの全面ブロックが残っていないかを必ず確認したいところです。
Allow
Allowは、Disallowで広く止めた範囲の中から、特定パスだけ許可したいときに使います。
User-agent: * Disallow: /member/ Allow: /member/public-guide.html
会員向けディレクトリ全体は抑えつつ、案内ページだけは読ませたい、といった場面で使えます。大規模サイトではこの例外指定が増えがちですが、例外が多すぎるならURL設計自体を見直したほうが運用しやすいです。
Sitemap
Sitemapは、XMLサイトマップの場所を伝えるための行です。
Sitemap: https://www.example.com/sitemap.xml
必須ではありませんが、記載しておくとクローラーにサイト構造を伝えやすくなります。特に新規公開直後やページ数の多いサイトでは、robots.txtとサイトマップの整合性を取っておくと管理しやすいです。
⇒XMLサイトマップの詳細は、XMLサイトマップ(sitemap.xml)とは?SEO効果や作成、設置方法で詳しく解説しています。
robots.txtの設置場所と有効範囲
robots.txtは、必ず対象サイトのルートに置く必要があります。サブディレクトリに置いても、robots.txtとしては認識されません。
たとえば、https://example.com のルールを制御したいなら、配置場所は以下です。
https://example.com/robots.txt
有効範囲はホスト・プロトコル・ポートごとに分かれる
この点は見落とされやすいですが、robots.txtの効力はサイト全体に無条件で広がるわけではありません。
- https://example.com/robots.txt は https://example.com/ 配下に適用
- https://www.example.com/robots.txt は www サブドメインにのみ適用
- http と https は別扱い
- ポート番号が違えば別扱い
つまり、wwwあり・なしが混在している環境や、m.example.comのような別サブドメイン運用では、それぞれ個別に確認が必要です。移行時やリニューアル時に「片方だけ直して満足していた」というミスは起こりやすいです。
ファイル形式でもつまずきやすい
robots.txtはプレーンテキストで保存し、UTF-8で扱うのが基本です。WordやGoogleドキュメントのようなワープロ系ツールで作ると、余計な文字や形式が混ざることがあります。
また、ファイル名の大文字小文字も雑に扱わないほうが安全です。robots.txtはURLとして参照されるため、配置ミスや命名ミスがあると、設定したつもりでも読まれていない状態になり得ます。
(参照:robots.txt の書き方、設定と送信)
そのまま使えるrobots.txtの記述例
実務では、ゼロから考えるより、目的別の型をもとに調整するほうが早いです。ここではよく使うパターンを整理します。
全クローラーに通常クロールを許可する
特にブロックしたいURLがない場合は、以下のようにシンプルで十分です。
User-agent: * Disallow: Sitemap: https://www.example.com/sitemap.xml
「何も止めない」ことを明示したいときに使えます。CMSによっては初期状態でrobots.txtが自動生成されることもありますが、内容は必ず確認したほうが安全です。
サイト内検索結果ページを止める
検索結果ページや絞り込みURLが増えやすいサイトでは、次のような制御がよく使われます。
User-agent: * Disallow: /search/ Disallow: /?s= Sitemap: https://www.example.com/sitemap.xml
ただし、クエリパラメータ付きURLの扱いはCMSやルーティング設計で変わります。実際には、どのURLが生成されているかをログやクロール結果で確認してから決めるのが確実です。
特定ディレクトリだけ止めて一部ページは許可する
会員向けや一時ファイル用のディレクトリで、例外ページだけ読ませたい場合の例です。
User-agent: * Disallow: /private/ Allow: /private/guide.html Sitemap: https://www.example.com/sitemap.xml
このような例外指定は便利ですが、ルールが複雑になるほど保守が難しくなります。更新担当者が複数いるサイトでは、どのURLを止めているのか一覧化しておくことがおすすめです。
robots.txtの設定手順
設定作業は、作成して終わりではありません。「作る→置く→見えるか確認する→意図通りに効くか確かめる」の4段階で進めると失敗しにくいです。
1. テキストファイルを作成する
メモ帳やコードエディタなど、プレーンテキストで保存できるツールを使います。まずは必要最小限のルールだけを書き、後から足すほうが安全です。
User-agent: * Disallow: /search/ Sitemap: https://www.example.com/sitemap.xml
2. ルートディレクトリにアップロードする
アップロード先は、対象ホストの最上位です。/folder/robots.txt のような場所では認識されません。
FTPやサーバー管理画面から配置したら、ブラウザで /robots.txt に直接アクセスし、内容がそのまま表示されるか確認します。404やリダイレクトが返るなら、設置場所か公開設定を見直す必要があります。
3. ブロック対象URLを具体的に確認する
設定後は、止めたいURLが本当に止まっているかを確認します。たとえば、ECで「色=黒」「サイズ=27cm」のような絞り込みURL、地域名だけ差し替えた店舗一覧URL、社内テスト用の確認ページなど、実際に発生しているURLで見ることが重要です。
ここを抽象的に済ませると、/search/ は止まっているのに /search/result/ は生きている、といった抜け漏れが残ります。パターン単位ではなく、実URL単位で確認するのが実務では分かりやすいです。
4. 反映タイミングも考慮する
robots.txtは更新直後に全クローラーへ即時反映されるとは限りません。Googleはrobots.txtをキャッシュするため、修正後もしばらく古い内容で解釈されることがあります。
そのため、設定変更の直後に「まだ効いていない」と慌てず、クロール状況やログもあわせて見て判断することが大切です。大きな変更を入れる日は、関係者が把握しやすいよう変更履歴を残しておくと運用しやすくなります。
robots.txtの確認方法
確認は、ファイルの存在確認だけでは不十分です。「読めるか」「書式が妥当か」「意図したURLが対象か」の3点を分けて確認します。
ブラウザで /robots.txt を直接開く
最初にやるべきなのは、対象ドメインの /robots.txt にアクセスすることです。ブラウザで開いて内容がそのまま表示されれば、少なくとも公開状態は確認できます。
ここでHTMLが返ってきたり、ログイン画面に飛んだり、404になる場合は、設定以前の問題です。まず公開場所を直す必要があります。
Search Consoleやサーバーログで挙動を見る
Search Consoleでは、クロールやインデックスの状態から間接的に影響を確認できます。加えて、サーバーログを見られる環境なら、特定パスへのGooglebotのアクセス推移を見ると、設定変更の影響を把握しやすくなります。
当社でもクロール制御の確認では、管理画面上の表示だけで判断せず、実際のアクセスログや対象URLの挙動まで見ることがあります。特に大規模サイトでは、1行の設定変更が想定以上の範囲に効くことがあるためです。
site:検索は補助的に使う
Google検索で site:example.com のように調べる方法は、ざっくりした確認には使えます。ただし、これだけでrobots.txtの成否を断定するのは危険です。
理由は、robots.txtでブロックしていてもURLだけ表示されることがあるためです。site:検索で出てきたから失敗、出てこないから成功、とは限りません。検索結果の有無より、クロール制御の意図と実際の挙動が一致しているかを見ることが重要です。
⇒Search Consoleの使い方を整理したい場合は、Googleサーチコンソールとは?機能や設定方法、使い方などを初心者にわかりやすく解説も是非参照ください。
robots.txtでやってはいけない設定
robots.txtは便利ですが、誤用するとSEOに悪影響が出ます。特に危険なのは、「検索結果から消したいページ」をrobots.txtだけで処理しようとすることです。
本番サイト全体をDisallow: / にしてしまう
もっとも分かりやすい事故がこれです。
User-agent: * Disallow: /
開発環境では妥当でも、本番で残ると主要ページまでクロールされません。リニューアル公開時、ステージング環境の設定がそのまま残る事故は今でも起こります。公開前チェックリストにrobots.txt確認を入れておくと防ぎやすいです。
CSSやJavaScriptをむやみに止める
レンダリングに必要なCSSやJavaScriptをブロックすると、検索エンジンがページを正しく理解しにくくなります。見た目には問題なくても、クローラー側では比較表やタブ切り替えの中身が十分に把握できていないことがあります。
特に、スマホ版だけ重要要素がJS依存になっているサイトでは注意が必要です。不要リソースのつもりで止めた結果、主要ページの理解精度まで落とすことがあります。
⇒モバイル対応の考え方は、モバイルフレンドリーとは?SEO対策で必要な理由や確認・対応方法で整理しています。
非公開情報の保護手段として使う
robots.txtはアクセス制御ではありません。URLを知っているユーザーは普通に閲覧できますし、悪意あるクローラーが必ず従う保証もありません。
社内資料、会員限定情報、検証中ページなど、本当に見せたくないものは認証やパスワード保護で守るべきです。ここを取り違えると、SEOの問題ではなく情報管理の問題になります。
2026年時点でのrobots.txt運用ポイント
2026年のSEO実務では、robots.txtは「とりあえず置くファイル」ではなく、URL管理の一部として設計するものになっています。
AI Overviewや各種検索機能の拡張で検索結果の見え方は変わっていますが、基礎として重要なのは依然として「どのURLをクロール・評価対象にしたいか」を明確にすることです。robots.txtだけで順位が上がるわけではないものの、評価させたいURLが散らばっている状態を放置すると、コンテンツ改善の効果も出にくくなります。
パラメータURLと重複URLの整理が重要
昨今はCMSやアプリ連携でURLが増えやすく、並び替え、絞り込み、計測パラメータ、セッション違いなどで評価対象がぼやけやすいです。robots.txtはその一部を整理する手段として有効ですが、canonicalや内部リンク設計とセットで考える必要があります。
ここをrobots.txt単独で解決しようとすると、クロールは減っても評価の集約が進まないことがあります。クロール制御は、URL正規化の補助として使うのが現実的です。
⇒URL正規化については、canonical(カノニカル)とは?URLの正規化でSEO対策を進めようもあわせてご覧ください。
変更履歴を残す運用が欠かせない
robots.txtは1ファイルなので軽く見られがちですが、影響範囲は広いです。誰がいつ何を変えたか分からない状態だと、順位変動やインデックス減少の原因追跡が難しくなります。
実務では、更新日、変更内容、対象ディレクトリ、意図を簡単に残しておくだけでも十分です。特に代理店、制作会社、社内運用担当が分かれている体制では、履歴管理の有無でトラブル対応の速さが変わります。
よくある質問
robots.txtがないとSEOで不利になりますか?
必ずしも不利にはなりません。不要URLが少ない小規模サイトなら、robots.txtを細かく設定しなくても問題ないことがあります。必要なのは、クロールを整理したい理由があるかどうかです。
robots.txtでブロックしたページは検索結果に出ませんか?
出ないとは言い切れません。外部や内部からURLが見つかれば、内容を読まれなくてもURLだけ検索結果に表示されることがあります。検索結果から確実に外したいなら、noindexや認証など別の方法を検討します。
robots.txtとmeta robotsは同時に使えますか?
使えますが、目的を分けて考える必要があります。meta robotsのnoindexを認識させたいなら、まずそのページがクロール可能であることが前提です。robots.txtで先に止めると、noindexが読まれないことがあります。
robots.txtは変更後すぐ反映されますか?
即時とは限りません。クローラー側でキャッシュされるため、反映まで時間差が出ることがあります。変更直後は、公開状態、ログ、クロール状況をあわせて確認するのが安全です。
robots.txtでユーザーの閲覧も止められますか?
止められません。robots.txtはクローラー向けの指示であり、ユーザーアクセスを制御する仕組みではありません。閲覧制限が必要なら、ログイン制御やパスワード保護を使います。
まとめ
robots.txtは、検索エンジンに対してクロール先を伝えるためのファイルであり、検索結果からページを消す仕組みではありません。重要なのは、noindexとの役割の違いを理解し、不要URLの整理にだけ使うことです。
特に、絞り込みURLや検索結果ページが増えやすいサイトでは、robots.txtの設計がクロール効率の改善につながります。一方で、本番全体のブロックや非公開情報の保護目的で使うのは避けるべきです。
robots.txtを触るときは、書き方そのものより「どのURLを評価対象にしたいか」を先に整理することが失敗防止になります。内部対策全体もあわせて見直したい方は、以下の情報も是非ご覧ください。
