
先日、2026年6月3日から5日にかけてボストンで開催された「SMX Advanced」に参加しました。検索とAIの最前線が集まるカンファレンスで、最も議論が集中していたテーマの一つが、構造化データとエンティティ(実体)の扱いです。
当社のこれまでを正直に振り返ると、SEOだけを対策していた時代は、構造化データへの対応は最小限にとどめていました。それでも十分に成果は出ていたのです。Googleの解釈能力が非常に高く、多少マークアップが不足していても、コンテンツの中身さえ良ければ正しく評価してくれたからです。
しかし、LLMO(AI検索最適化)の時代に入り、前提が変わりました。ChatGPTやGeminiをはじめ、多様なAIクローラーが次々と生まれています。それぞれがページの意味を読み取ろうとする今、構造化データで「自社が何者で、何を発信しているのか」を明示する意味は、かつてないほど大きくなっています。
そこで当社は、SMXでの学びを踏まえ、自社サイト全体の構造化データを点検し、AI検索時代に合わせて実装し直しました。本記事は、その実体験をもとに、構造化データの基礎から、SEOとLLMOで重要になる理由、具体的な実装と検証方法までを体系的に解説します。検索結果の1ページ目には入るのに上位が取れない、クリック率が伸びない——といった課題の打開にもつながるテーマです。

この記事でわかること
動画でわかる構造化データの全体像
記事の要点を先に動画で掴みたい方は、以下をご覧ください。(動画をクリックすると音声が出ます)
構造化データとは?検索エンジンとAIにページの意味を伝える仕組み
構造化データとは、ページに記載された情報が「何を意味するのか」を、検索エンジンやAIが正確に解釈できる形式で明示する仕組みです。
Webページ上のテキストや画像は、人間であれば「これは会社名」「これは営業時間」と直感的に判断できます。一方、コンピューターはそれらを「文字列」「画像」としてしか認識できず、意味までは読み取れません。
構造化データは、こうした情報に「これは会社名」「これは公開日」といった意味のラベルを付与します。これにより、検索エンジンやAIは、ページの内容をより正確に理解できるようになります。
この考え方の基盤にあるのが「セマンティックWeb」です。Web上のあらゆる情報に「それが何の情報か」を示すメタデータを付与し、機械にも意味を理解させようという構想で、W3C創始者のティム・バーナーズ=リー氏によって提唱されました。Googleのリッチリザルトは、その代表的な実用例です。構造化データは、このセマンティックWebの思想を、実務で活用できる形にしたものと捉えると理解しやすいでしょう。
近年は、この「意味を機械に伝える」役割が、検索エンジンにとどまらずAIにも及ぶようになりました。ChatGPT、Gemini、AI Overviewsといった生成AIがページ内容を解釈する場面でも、構造化データが参照されるようになっています。これが、2026年に構造化データを論じるうえで欠かせない視点です。
なぜ今、構造化データがSEOとLLMOで重要なのか
構造化データの重要性が高まっている理由は、大きく二つに整理できます。SEOの観点と、LLMO(AI検索最適化)の観点です。そして近年、後者の比重が急速に増しています。
SEOの観点:リッチリザルトでクリック率を高める
一つ目は、従来からのSEO効果です。マークアップした情報は、検索結果にリッチリザルト(通常のリンクに加えて表示される星評価・画像・パンくずなどの補足情報)として表示される可能性があります。検索結果内での視認性が高まり、クリック率の向上が期待できます。
LLMOの観点:多様なAIクローラーに「誰が・何を」を正確に伝える
冒頭でも述べたとおり、SEOだけの時代は、構造化データへの対応は最小限でも成果が出ていました。Googleの解釈能力が高く、中身さえ良ければ正しく評価されたためです。
ところが、AI検索の時代に入り、前提が変わりました。ChatGPT、Gemini、Perplexity、各社のAIクローラーが、それぞれの基準でページの意味を読み取ろうとしています。読み手が「Google一つ」から「多様なAI」へ広がったことで、構造化データで自社の情報を明示しておく意味が、格段に大きくなりました。
ここで押さえておきたいのは、構造化データは「実装すればAIに引用される」ものではないという点です。Googleも、AI Overviewsに表示されるために特別な構造化データやマークアップは不要であり、通常のSEOと同じ技術要件を満たせばよいと公式に説明しています。
では、何のために実装するのか。AIに対して「この記事は誰が執筆し」「どの企業が運営し」「何を専門とするサイトなのか」を、誤解なく伝えるためです。本文だけでは取りこぼされかねない発信主体や専門性の情報を、機械が解釈しやすい形で整理しておく。いわば、AIが内容を正確に読み取るための"補助線"としての役割です。
当社は構造化データを、検索順位を操作するための手法ではなく、自社の情報を検索エンジンとAIに誤解なく伝える「翻訳レイヤー」と位置付けています。この考え方が、以降で述べる実装判断すべての基準になります。
構造化データで期待できるSEO効果(順位を直接上げる施策ではない)
効果を整理する前に、最初に重要な前提を確認します。
構造化データの実装そのものによって、検索順位が直接上がることはありません。順位を決定づけるのは、あくまでコンテンツの内容と質です。これはGoogleが一貫して示している見解であり、当社の実感とも一致します。
そのうえで、構造化データには次のような効果があります。
検索エンジンがページ内容を正しく理解する
情報にラベルが付与されることで、検索エンジンは「運営者が何を伝えようとしている記事なのか」を正しく把握できるようになります。評価の土台となる理解の精度が高まる、という効果です。
リッチリザルトでクリック率が高まる
マークアップした情報がリッチリザルトとして表示されれば、検索結果での視認性が向上し、クリック率の改善につながります。ただし、その前提として、コンテンツの質と検索順位が伴っている必要があります。内容が十分でない場合、リッチリザルトは表示されません。
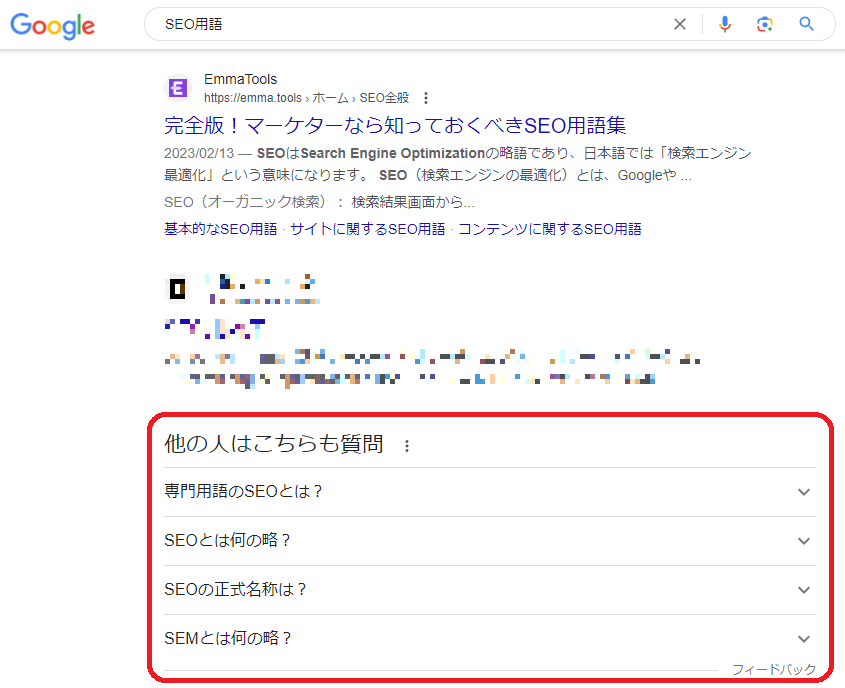
ローカルSEO(店舗ビジネス)に効果がある
構造化データには「LocalBusiness」という型があり、営業時間・住所・地図などを設定できます。地域検索で表示された際にナレッジパネルへ店舗情報が表示され、経路案内や予約・注文への導線となります。実店舗を持つビジネスでは、効果が明確に表れやすい領域です。
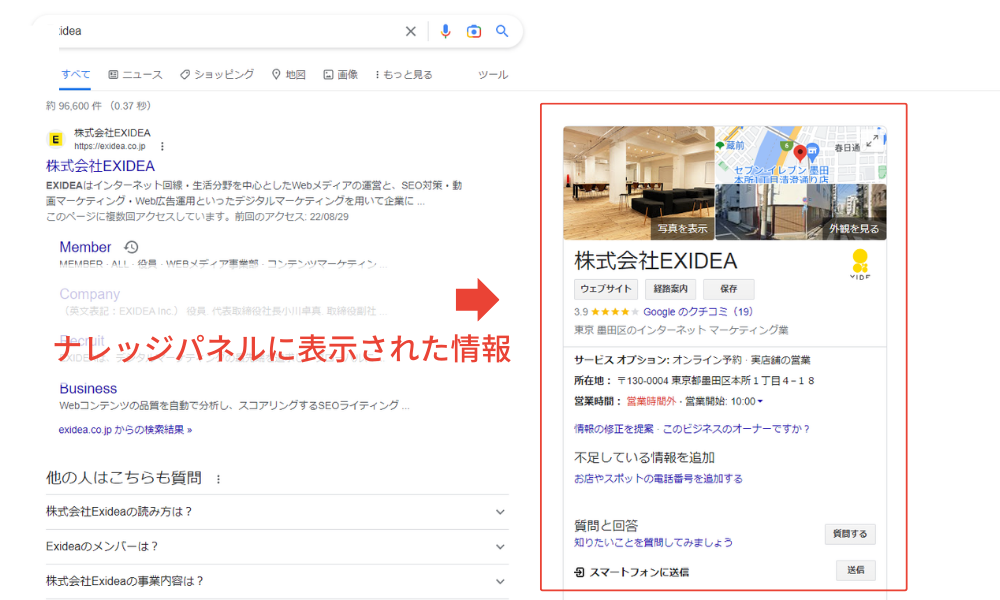
整理すると、構造化データの効果は「順位の向上」ではなく、「内容を正確に理解されること」と「検索結果での視認性が高まること」の二点に集約されます。
LLMO・AI検索時代に構造化データで伝えるべき情報
本記事で特にお伝えしたいのが、この章です。
AIに自社を正確に認識させるうえで、特に効果的な構造化データは限られています。当社が自社サイトへの実装を通じて有効性を確認しているのは、次の3つです。
- Organization + sameAs:運営会社が何者か。公式サイト・SNS・外部プロフィールと紐づけ、その実体を明確にする
- Article + Author / Person:その記事を誰が執筆し、誰が監修したのか。専門性の出どころを示す
- BreadcrumbList:サイトの構造と、その記事がどの文脈に位置づくのかを伝える
冒頭で述べた自社実装でも、この3点を軸に整備しました。トップページにはOrganizationとsameAsを設定し、公式のFacebook・Instagram・YouTubeと紐づけることで、「当サイトは株式会社EXIDEAが運営している」とAIが裏付けを取れる状態にしています。各記事にはArticle・著者・パンくずを実装し、「誰が執筆した、何の記事か」を機械にも明確に伝えています。
エンティティとして「孤立させず、つなぐ」
SMX Advancedのセッションで、構造化データの専門家が共通して強調していたのが、この点でした。個々のページに構造化データを入れるだけでは不十分で、それらを相互に接続し、運営組織や著者と結びつけることが重要だ、という指摘です。ページ単体ではなく、エンティティ(実体)とその関係性でAIに理解させる、という発想です。
接続の鍵になるのは、主に次の要素です。
- @id:各エンティティに固有の識別子を与え、ページをまたいで同一の実体として扱えるようにする
- sameAs:Wikipedia・公式SNSなど、外部の信頼できる情報源と結びつけて実体を裏付ける
- about / mentions:そのページが何について述べ、どの関連エンティティに触れているかを示す
- 組織への接続:記事を著者と運営会社に、商品をブランドに結びつけ、孤立した「島」にしない
当社も、この考え方に沿って実装し直しました。各記事のArticleを著者(Person)と運営組織(Organization)に@idで接続し、著者である代表・小川のPersonエンティティには、Wikipedia・X・noteをsameAsで紐づけています。これにより、AIはページ単位ではなく、「誰が・どの組織で・何を発信しているのか」というエンティティと関係性で情報を解釈しやすくなります。Grant Simmons氏のセッションで紹介されていた「Entity Map」のように、サイトの意味構造そのものをAI向けに明示する取り組みも始まっており、この方向性は今後さらに重要になると考えています。
【ページタイプ別】実装すべき構造化データ一覧
構造化データは「実装できるものをすべて入れる」ものではありません。サイトの種類と、達成したい目的によって、優先順位は変わります。当社が目的別に整理している早見表が、以下です。
| サイトタイプ | 集客・CTR | CVR向上 | LLMO / AI検索 | まず実装したい構造化データ |
|---|---|---|---|---|
| オウンドメディア | 記事理解・パンくず | 著者信頼・関連導線 | 著者・運営者・専門領域 | Article / BreadcrumbList / Person / Organization |
| BtoB SaaS | 課題解決記事の理解 | サービス理解・資料請求 | サービス領域の認識 | Article / Service / Organization / Person |
| ECサイト | 商品検索・リッチリザルト | 価格・在庫・レビュー | 商品情報の正確な理解 | Product / Offer / Review / AggregateRating |
| 店舗・ローカル | 地域検索対応 | 来店・予約促進 | 店舗情報の明確化 | LocalBusiness / PostalAddress / OpeningHours |
| 求人・採用 | 求人検索対応 | 応募前情報の明確化 | 会社・職種の理解 | JobPosting / Organization |
| 動画メディア | 動画検索・サムネイル | 視聴・問い合わせ導線 | 動画内容のAI理解 | VideoObject / Article |
| 比較メディア | 比較軸の理解 | 選定支援 | 一覧・ランキング構造 | ItemList / Product / Review / BreadcrumbList |
まず着手すべきは、全サイト共通の基本3点——BreadcrumbList・Article・Organization(+WebSite)です。この3点を整えるだけで、サイト・記事・運営者という土台情報が正確に伝わります。ProductやLocalBusinessといった業種別の型は、その後に必要なものを追加していく方針が効率的です。
構造化データの書き方|JSON-LD実装例
記述仕様(シンタックス)にはJSON-LD・Microdata・RDFaの3種類がありますが、Googleが推奨しているのはJSON-LDです。HTML本体と分離して記述できるため保守性が高く、修正・更新も容易です。新規に実装する場合は、JSON-LDで統一することを推奨します。
定義(ボキャブラリ)はschema.orgから該当する型を選択します。以下は、当社が実際に自社メディアの全記事へ実装している構成で、Article + Author + Organization + BreadcrumbList を@idで接続した例です。
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@graph": [
{
"@type": "Article",
"@id": "https://example.com/article#article",
"headline": "構造化データとは?SEO・AI検索(LLMO)で重要な理由と実装方法を解説",
"datePublished": "2026-06-15T09:00:00+09:00",
"dateModified": "2026-06-15T09:00:00+09:00",
"author": { "@id": "https://example.com/author#person" },
"publisher": { "@id": "https://example.com/#organization" }
},
{
"@type": "Person",
"@id": "https://example.com/author#person",
"name": "小川 卓真",
"jobTitle": "株式会社EXIDEA 代表取締役社長",
"sameAs": [
"https://x.com/Ogawa_Takuma_",
"https://note.com/exidea_ogawa",
"https://ja.wikipedia.org/wiki/小川卓真"
]
},
{
"@type": "Organization",
"@id": "https://example.com/#organization",
"name": "EmmaTools",
"url": "https://emma.tools/",
"parentOrganization": {
"@type": "Organization",
"name": "株式会社EXIDEA",
"sameAs": [
"https://www.facebook.com/exidea/",
"https://www.instagram.com/exidea_growth_hackers/",
"https://www.youtube.com/@exidea8033"
]
}
}
]
}
</script>
ポイントは、@idで各エンティティを参照し合い、sameAsで外部の信頼ソースに接続している点です。著者のsameAsにWikipediaや公式SNSを並べることで、「このPersonが実在のどの人物か」をAIや検索エンジンが照合できます。前章で述べた「孤立させず、つなぐ」を、コードに落とし込んだ形です。
店舗ビジネスであればLocalBusiness、ECであればProductというように、ページの内容に応じて型を選択します。型を問わず共通して守るべき原則は一つ、ページに実際に表示されている情報のみをマークアップすることです。店舗名や住所を構造化データに記述するのであれば、その情報は本文にも記載されている必要があります。
構造化データの確認・検証方法
実装後の検証は欠かせません。当社の実装時にも確認しましたが、「実装したつもりで、正しく認識されていない」というケースは少なくありません。シンタックスの誤りや必須項目の欠落により、構造化データとして読み取られていないためです。
主な確認手段は3つです。
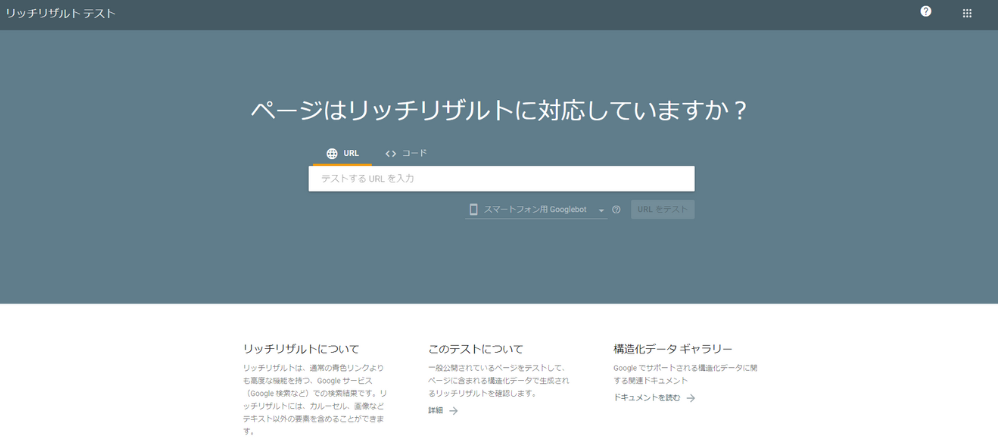
リッチリザルトテスト
リッチリザルトテストは、公開済みのURLまたはコードを直接入力して確認できます。正しく認識されていれば、どの型が検出されたかが表示されます。実装直後の一次チェックに適しています。
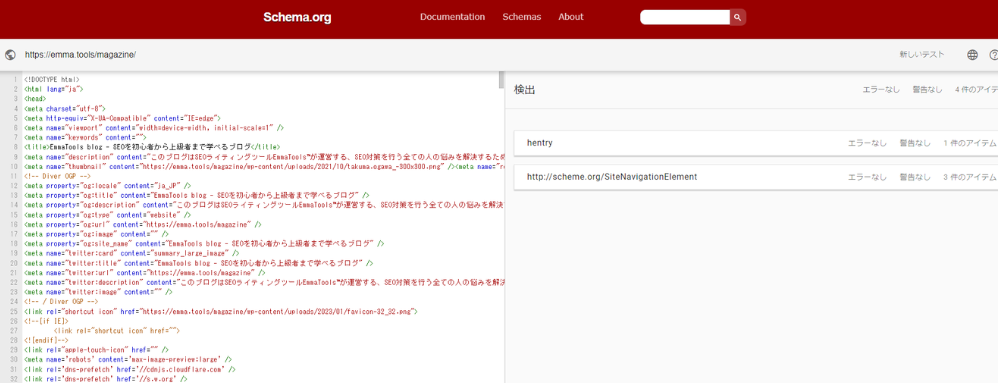
スキーママークアップ検証ツール
スキーママークアップ検証ツール(旧・構造化データテストツール)は、schema.orgの仕様に沿って各項目が正しく読み取られているかを確認できます。値がどの型に対応しているかを項目ごとに確認できるため、構造が複雑な場合の検証に適しています。
Google Search Consoleの「拡張」レポート
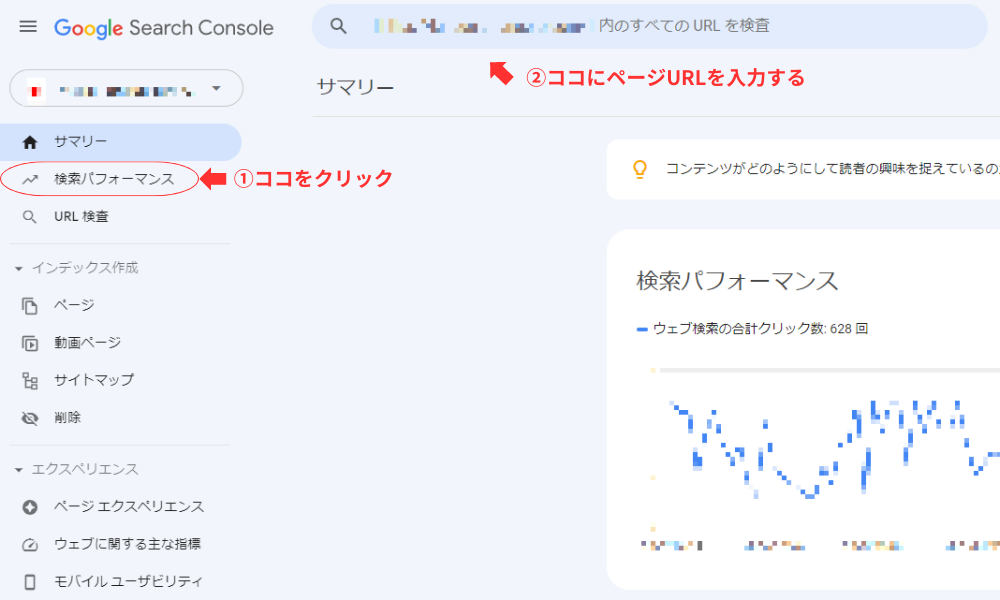
公開後の継続的な監視には、Search Consoleが適しています。URL検査で個別ページを確認できるほか、「拡張」セクションに「記事」「パンくずリスト」などの項目が表示され、サイト全体のエラーや警告をまとめて把握できます。反映には数日から数週間を要します。当社でも、実装後はこのレポートを継続的に確認しています。
実装時に押さえておきたい注意点
構造化データは、誤った実装をすると「効果が出ない」だけでなく、検索エンジンに誤解を与える要因にもなり得ます。当社の実装経験も踏まえ、注意点を整理します。
ページに表示されていない情報をマークアップしない
最も重要な原則です。Googleのガイドラインでも、ユーザーに見えない情報や本文と矛盾する情報のマークアップは問題となり得ると示されています。構造化データはあくまで本文の内容を伝えるものであり、本文にない情報を補うためのものではありません。
FAQ・HowToをリッチリザルト目的で実装しない
2026年時点で押さえておくべき重要な変化があります。FAQリッチリザルトの表示は、2026年5月7日をもって終了しました。HowToリッチリザルトは、それ以前の2023年9月に廃止されています。
そのため、FAQPageやHowToを実装しても、従来のように検索結果で目立つ枠が表示されることは期待できません。ただし、FAQという形式自体が無意味になったわけではありません。ユーザーの疑問に明確に回答する構成は引き続き重要であり、整理されたQ&AはAIがページの意味を理解するための補助として機能します。リッチリザルトの獲得を目的とするのではなく、理解の補助として位置付けるのが適切です。
schemaを「孤立させない」
ページごとに構造化データを入れていても、それらが運営組織や著者とつながっていなければ、文脈が弱くなります。前章で触れたとおり、AIはエンティティと関係性で情報を理解するため、孤立した構造化データは効果が限定的になります。@idで著者・組織に接続し、サイト全体で一つの意味グラフを形成することが重要です。当社も、当初は記事の構造化データが運営組織と接続されていない状態でしたが、今回これを接続する形に改めました。
WordPressでは「二重出力」に注意する
WordPressでは、テーマ・SEOプラグイン・構造化データ専用プラグイン・自前実装が、それぞれ個別にschemaを出力していることがあります。同一のArticleが重複したり、Organization情報が矛盾したりする原因となるため、まず現在どのschemaが出力されているかを確認し、出力元を一元化することが重要です。
当社EXIDEAが考える構造化データ実装の本質
当社では、構造化データを「リッチリザルトを獲得するためのSEOテクニック」とは捉えていません。検索エンジンとAIに、ページの意味を誤解なく伝える翻訳レイヤー。これが基本的な位置づけです。AI検索やLLMOが普及するほど、この「正しく伝わっているか」の重要性は増しています。
運用において重視しているのは3点です。JSON-LDを第一候補とすること(Googleが推奨しており、本文と分離して保守できる)。増やすことより、正確に実装すること(見えない情報は記述せず、本文と一致させる)。そして孤立させず、@idで著者・組織につなぐこと(ページ単体ではなく、エンティティと関係性で理解させる)。
優先順位は「リッチリザルトが表示されるか」ではなく、「AIや検索エンジンに誤解されたくない重要な情報か」で判断します。リッチリザルトは結果であって、目的ではありません。自社が何を専門とし、誰が執筆し、どの企業が運営しているのか。それをサイト全体で一貫して伝えられているかどうか。構造化データの本質は、そこにあると考えています。
よくある質問
構造化データを入れれば必ずリッチリザルトが表示されますか?
表示されるとは限りません。構造化データは「リッチリザルトの候補になる」シグナルであり、最終的な表示判断はGoogle側で行われます。同じ実装でも、検索クエリやデバイス、サイトの信頼性によって表示の有無は変わります。
構造化データはSEO順位に直接影響しますか?
直接的な順位要因ではない、というのがGoogleの公式見解です。ただし、リッチリザルトによるCTR向上や、ページ内容の正確な伝達、AI検索での参照されやすさを通じて、結果的に検索パフォーマンスへ影響する可能性はあります。
JSON-LDとMicrodataはどちらが良いですか?
Googleが推奨しているのはJSON-LDです。HTML本体から分離されているため保守がしやすく、修正・更新も容易です。新規に実装する場合は、JSON-LDで統一することを推奨します。
LLMO対策として、まず何から実装すべきですか?
Organization(+sameAs)・Article・Author/Person・BreadcrumbListの4点を、@idで相互に接続することをおすすめします。AIが「誰が運営し、誰が執筆した、何の記事か」をエンティティ単位で理解できる状態をつくることが、土台になります。
FAQの構造化データは、もう実装する意味がないのでしょうか?
リッチリザルト獲得という観点では、効果は期待しにくくなりました(FAQリッチリザルトは2026年5月7日に表示終了)。ただし、整理されたQ&Aは、読者にとってもページ内容を解釈するAIにとっても有用です。リッチリザルト目的ではなく、理解の補助として位置付けるのが適切です。
まとめ
SMX Advancedでの議論と、自社サイトへの実装を通じて、あらためて確認できたことがあります。構造化データは、検索順位を押し上げる施策でも、AIに引用されることを保証する施策でもありません。検索エンジンとAIに、自社の情報を誤解なく伝えるための「翻訳レイヤー」です。
SEOだけの時代は、最小限の対応でも成果が出ました。しかしAI検索の時代には、多様なクローラーに自社を正しく認識させるため、構造化データの役割は確実に大きくなっています。実装の優先順位は明確です。まずBreadcrumbList・Article・Organization(+sameAs)の基本3点で、サイト・記事・運営者を正確に伝える。それらを@idで接続し、孤立させない。業種別の型はその後に追加する。FAQやHowToはリッチリザルト獲得ではなく理解の補助として活用する。そして実装後は、検証ツールで正しく認識されているかを確認する。
ただし前提として忘れてはならないのは、構造化データはあくまで翻訳レイヤーであり、翻訳すべき中身——コンテンツそのものの質——が伴わなければ、リッチリザルトもAIでの参照も生まれないという点です。
EmmaToolsは、対策キーワードを入力するだけで競合上位ページの平均文字数・見出し構成・関連キーワードを提示し、コンテンツの質をスコアで可視化しながらライティング・リライトができるSEOツールです。構造化データで「正確に伝える」前提となる、伝えるに値する中身づくりにご活用いただけます。7日間の無料トライアルをご用意していますので、ぜひお試しください。
リッチリザルト対策を含むテクニカルSEOについては、別ページにまとめています。あわせてご一読ください。
