
robots.txtとは、検索エンジンがインターネット上にあるサイトから情報を収集するために巡回させているクローラーに、自社サイト内のアクセスして良いページがどれかを教えるために設置するファイルです。
記述方法は難しいものではなく、ルールを守ってrobots.txtを作成すれば、クローラーの回遊効率を改善し、より早く自社サイトの情報を検索エンジンのデータベースにインデックスできるようになります。
自社サイト内の重点的に巡回させたいページと、クローリングが不要なページへのクローラーのアクセスをコントロールできるrobots.txtの使い方をマスターしましょう。
この記事でわかること
動画でわかるクロール制御の全体像
記事の要点を先に動画で掴みたい方は、以下をご覧ください。(動画をクリックすると音声が出ます)
robots.txtとは
robots.txtは、検索エンジンからのクローラーがサイト内でアクセスできるファイルを制限するために作成、設置するテキストファイルです。
robots.txtファイルは、自社サイトを設置しているサーバ内のルートディレクトリに設置します。サイト内の見せたくないページやディレクトリを記述することでクローラーのアクセスを禁止し、重点的に巡回させたいファイルへ導くことができます。
このページでは、robots.txtを作成し、クローラーのサイト内でのアクセスをコントロールすることで得られるSEO効果について解説しています。robots.txtファイルの作成方法や、内容が正しく記述されているか、動作するかどうかの確認方法と、使用上の注意点についてもご紹介します。
robots.txtの最適化で得られるSEO効果
Googleをはじめとする検索エンジンは、クローラーと呼ばれるプログラム(ロボット)を使い、インターネット上に数多あるWebサイトの情報を収集しています。
また、検索エンジンの仕込みは、クローラーが各サイトを巡回し、情報を集め、データベースにインデックス(収納)させます。その後、独自のアルゴリズムでデータベース内のコンテンツに順位をつけ、検索結果に表示させます。
このように、インターネット上に公開されたコンテンツは、クローラーがサイトを巡回し情報を収集することから始まります。言い換えると、ユーザーに役立つ高品質なコンテンツを作成しても、クローラーが自社サイトを訪れなければ、検索エンジンにインデックスされないため、評価されないだけでなく検索結果画面に表示されません。
では、robots.txtを使い、クローラーがアクセスできる範囲を制限することに意味はあるのでしょうか?
クローラーを制限する意味
クローラーは、サイトにアクセスしても、一度にすべての情報を読み込んでいるわけではありません。クロールバジェットと呼ばれる、「制限枠」の中でページを読み込みます。
ページ数が増えると、ユーザーやクローラーに見せる必要がないページも出てきます。それらのページまでクローラーが回れば、制限枠を無駄に使うことになります。
効率よくサイト内にあるクローラーに読み取ってもらいたいページを巡回してもらうため、robots.txtは役立ちます。robots.txtを上手に使いこなし、クローラーにインデックスさせたいファイルを優先的に確認してもらいましょう。
noindexとの違いや使い分け
サイト内でのクローラーのアクセスを制限するrobots.txtファイルに似たものとして、noindexタグが挙げられます
noindexタグとは、指定したページを検索エンジンのデータベースにインデックスさせないために使うタグです。
robots.txtファイルとnoindexタグ、この2つの違いと、使い分ける方法について解説します。
noindexとの違い
先に紹介した通り、robots.txtは独立したテキストファイルで、検索エンジンからの「クローラーを制御する」ために設定します。
一方、noindexタグは各ページ内に記述するHTMLタグであり、インデックスというアクションそのものを制御し、「検索エンジンのデータベースにページ情報をインデックス(登録)させない」ために使います。
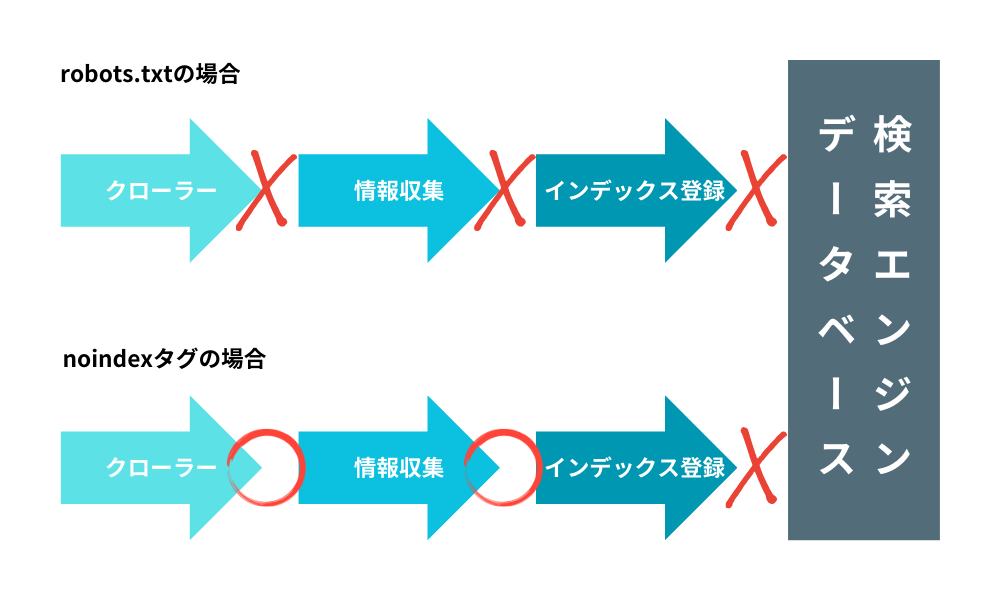
robots.txtファイルで指定されたページはクローラーがアクセスしないのに対し、noindexタグが記述されたページには、robots.txtファイルでアクセス制限をしていない限りクローラーが回ります。
robots.txtで制限されるとクローラーが届かず、robots.txtでクローラーのアクセス制限がなくnoindexタグが記載されたページは、クローラーが届いても検索エンジンのデータベースには登録しない、という違いがあります。
使い分けるタイミング
robots.txtファイルとnoindexタグ、この2つを使い分ける方法について、そもそも「目的」が違うことはお分かりでしょうか?
robots.txtファイルを使ってクローラーにアクセスさせないのは、「クローラーを効率的に回すため」(=早く検索エンジンに伝えたいファイルを届けて検索結果画面に反映させたい)です。
noindexタグが入ったページは「ユーザーに見せたくない、または見せる必要がない」ページを検索エンジンにインデックスさせないために使います。
インデックスさせたくないページには、例えば管理画面やテスト画面、情報入力ページやサンクスページ、さらに自動生成されてしまうページなどがあります。クローラー(クローリング)とインデックスの違いを理解し、robots.txtファイルとnoindexタグを正しく使い分けましょう。
noindexタグについては『noindexとは?設定方法と注意点を2026年版で解説』で詳しく解説しています。以下のページをご覧ください。
robots.txtの基本情報
SEO対策にもなるrobots.txtファイルの使い方を知っておきましょう。
そのためにはまず、robots.txtがどのようなテキストファイルなのかを知る必要があります。robots.txt内は大きく分けて3つの要素があり、それぞれ指定された書き方で、必要情報をメモ帳などのテキストエディタを使って入力します。以下は記入例です。
1.User-agent: * 2.Disallow: / 3.Sitemap: https://www.aaa.co.jp/sitemap.xml
各項目について解説します。
1.User-Agent
まずUser-Agentという項目で「どのクローラーに対して」ファイルを実行するかを指定します。
すべてのクローラーの場合は「*」(アスタリスク)、その他それぞれの検索エンジンのクローラーを指定する場合は、Googleのクローラー概要ページを参照しましょう。
2.DisallowとAllow
続いてクローラーの各ファイルへのアクセス可不可を決めるDisallowとAllowの項目を入力します。
記述方法はDisallow:(コロン)またはAllow:の後にURLパスを入力します。Disallow:/だとクローラーはすべてのファイルにアクセスできません。URLパスだけでなく、ディレクトリ管理をしている場合はディレクトリを指定することでその中にあるファイルへのアクセス可不可を指定できます(例:Disallow:abc.co.jp/filea/)。
3.Sitemap
サイト内の構造を伝えるXMLサイトマップ(sitemap.xml)ファイルの位置をrobots.txtファイルでも伝えることができます。
ただし、この項目は必須ではなく任意であり、sitemap.xmlファイルを作成していない場合には記述する必要がありません。sitemap.xmlファイルを使っている場合は指定しておきましょう。ディレクトリ毎に設定してる場合にはそれぞれ指定することができます。
robots.txtの正しい書き方と確認の流れ
robots.txtファイルの内容を理解したところで、次は作り方と確認・設定方法をご紹介します。
1.書き方と参考例
メモ帳などのテキストエディタを開き、以下をコピーしてください。
User-agent: * Disallow: / Sitemap: https://www.aaa.co.jp/sitemap.xml
こちらは1行目で「すべてのクローラー」に対し、2行目で「サイト全体」にアクセスを禁止するよう指定、3行目にはxmlファイルの設置場所を伝える記述をしてあります。それぞれ記述を変更することで「どのクローラー」が「サイト内のどこまでアクセスできるか」を指定できます。
例えば、「Googleのクローラー、Googlebot」を「abc」というディレクトリにアクセスをさせない場合、下記の記述内容に変わります。
User-agent: Googlebot Disallow: /abc/ Sitemap: https://www.aaa.co.jp/sitemap.xml
ただし、「abc」ディレクトリの中の、「bbb.html」というファイルはクローラーに読ませるためアクセスを許可する場合は以下となります。
User-agent: Googlebot Disallow: /abc/ Allow:/abc/bbb.html Sitemap: https://www.aaa.co.jp/sitemap.xml
このrobots.txtが設置されたサイトにアクセスしたGoogleのクローラー(Googlebot)は、abcディレクトリ内は基本的にアクセス不可、ただし/abc/bbb.htmlにはアクセスしてGoogleにインデックスしてもらうよう促しています。
2.robots.txtファイルの設置方法
上記で作成したrobots.txtファイルをサイトファイルが置いてあるサーバーにアップロードします。
robots.txtファイルを設置する場所は、ルートドメイン上になります。FTPを使ってアップロードしましょう。
注意点として、ルートドメイン以外に設置してもrobots.txtファイルは動作しません。必ずサーバ内のサイト情報に関するデータが保存されているフォルダの最上位に設置しましょう。
3.テスターを活用し正しく記述できているか確認
robots.txtファイルの設置が完了したら、記述が正しいかチェックしましょう。Google サーチコンソールに登録し、ログインしたらrobots.txtテスターツールにアクセスしましょう。
このページで、もし記述内容に間違いがあれば、エラーまたは警告が出ます。指示されている部分を訂正しましょう。
エラーや警告が0になっていることを確認したら、画面下にある空欄部分、「URLがブロックされているかどうかテストするには、URLを入力してください」と出ている部分にアクセスさせたくないURLを入力し、その右にあるプルダウンメニューから指定クローラーを選んで「テスト」ボタンをクリックします。
クローラーが読み込めない状態になっていれば「ブロック済み」と表示されます。
4.実際に検索して確かめる
テスターを使ってrobots.txtが正常であることを確認したら、最後に検索して表示されるかどうかを確認しましょう。
クローラーがアクセスしないよう指定したURLを検索エンジンに入力します。正しくrobots.txtが作動していれば、新しいページは検索結果画面に表示されません(既存ページのリライト後であれば更新内容が表示されません)。
robots.txtに関する注意点
robots.txtを正しく利用できれば、SEO効果が期待できます。しかし、robots.txtファイルには、使用に関して注意しなければならない点もあります。
新しいページのアクセス制限としてrobots.txtを使うと、クローラーが回らず情報収集をできないため、検索エンジンのデータベースにインデックスされません。既存ページの場合は、robots.txtファイルでアクセスを禁止する前までの情報が検索エンジンのデータベースにインデックスされています。
ページやデータそのものをインデックスから除外したい場合は、Google Search Consoleを使い指定ページのインデックスを消去するようリクエストした上で、ページ内にnoindexタグを記述しましょう。
また、robots.txtファイルはクローラーに対して有効なものであり、ユーザーのアクセスを制限するものではありません。
サイト内の内部リンクが設置されていたり、URLを知っている(お気に入り登録など)ユーザーは、ページにアクセスできて内容を閲覧できます。robots.txtでクローラーのアクセスを制限していても、外部サイトからの被リンクを受けている場合は、ページ情報が読み込まれてしまう可能性があるので注意しましょう。
robots.txtファイルは、アップロードしてもすぐには反映されません。検索エンジンの中にはrobots.txtでクローラーをブロックできないものがある、ということも覚えておきましょう。
当社EXIDEAが考えるrobots.txt運用の本質
当社では、robots.txtを「クロールを止めるためのファイル」ではなく、限られたクロールバジェットを重要ページに集中させるための交通整理として位置付けています。中小規模サイトではあまり意識する必要はありませんが、ECサイトや大規模メディアでは、robots.txt の設定一つで重要ページのインデックス速度が大きく変わります。
運用の基本動作は3つあります。1つ目は、robots.txtで「インデックスをブロック」しようとしないこと。よくある誤解ですが、robots.txtはクロール制御であり、インデックス制御ではありません。robots.txtで Disallow したページが、外部リンク経由で検索結果に表示されることがあります。検索結果に出したくないページには、robots.txtではなく noindex を使うのが正しい運用です。
2つ目は、サイトマップへのリンクを必ず記載すること。robots.txt の最後に「Sitemap: https://example.com/sitemap.xml」を追加することで、検索エンジンがサイトマップの場所を確実に発見できます。当社のクライアント支援でも、この一行が抜けているケースが意外と多く、追加するだけでクロール効率が改善します。
3つ目は、変更後はSearch Consoleで必ず検証すること。robots.txt の Disallow に typo があると、サイト全体がクロール不能になる事故が起きます。ファイル変更時には、Search Console の robots.txt テスター(または URL検査ツール)で、想定通りに動作しているかを確認するのが基本動作です。
よくある質問
robots.txtとnoindexはどう使い分けますか?
robots.txtはクロール制御、noindexはインデックス制御です。検索結果に表示させたくないページにはnoindexを使い、クロール自体を制限したい(クロールバジェット節約)場合にrobots.txtを使います。両方を併用すると、Googlebotがnoindex指定を読めず、想定通りに動作しない可能性があるので注意が必要です。
robots.txtを設置しないとSEOに悪影響がありますか?
中小規模サイトなら、設置しなくても大きな問題はありません。ただし、サイトマップの場所を伝えたい、特定ディレクトリのクロールを制限したい場合には設置をおすすめします。WordPressでは多くの場合、自動生成されたrobots.txtが既に存在します。
robots.txtで全ページを許可するにはどう書きますか?
「User-agent: *」の下に「Allow: /」または「Disallow: 」(空)を記述します。デフォルトでは全ページがクロール対象なので、特に制限しないなら最低限「User-agent: *」+「Sitemap: URL」だけ書いておけば十分です。
robots.txtに記述したのに検索結果からページが消えないのはなぜですか?
robots.txtはクロール制御で、インデックス削除の手段ではありません。すでにインデックスされているページや、外部リンクから情報を取得できるページは、robots.txtでブロックしても検索結果に残ることがあります。インデックスから完全に削除するには、noindexタグまたはSearch Consoleの削除ツールを使ってください。
大規模サイトでrobots.txtを最適化する目安は?
クロールバジェットの効率化が重要になります。検索結果に出す必要がないページ(検索フィルタの組み合わせURL、内部用URLなど)を Disallow し、重要ページのクロール頻度を上げる設計が有効です。Search Consoleの「クロールの統計情報」で実際のクロール状況を見ながら調整するのが現実的です。
まとめ
robots.txtファイルは、サイト運営を行う上で、必ず設置しなければならないファイルではありません。
クローラーによるサイト内の各ページへのアクセス管理を行なった方が良いのは、ページ数が1,000を超える中・大規模なサイトです。小規模なサイトであればクローラーの最適化は基本的に不要です。
サイトの成長に合わせ、必要になったときにrobots.txtファイルを作成し、SEOの内部対策を進めましょう。
robots.txtを作成すること以外の内部対策については、以下のページで紹介していますので、ぜひ、ご一読ください。
