
クローラビリティとは、検索エンジンのクローラーがWebサイト内のページを見つけやすく、巡回しやすく、内容を把握しやすい状態のことです。
クローラビリティが低いと、良いコンテンツを公開しても発見や再クロールが遅れ、インデックスや評価に時間がかかることがあります。特に2026年時点では、サイト規模の拡大、JavaScript依存、絞り込みURLの増加などで、URL管理の甘さがそのままクロール効率の低下につながりやすくなっています。
この記事では、クローラビリティの意味、SEOで重要な理由、改善・向上させる11の方法、実際にクロールされているかを確認する手順まで整理して解説します。自社サイトのクローラビリティを見直したい方は、ここからはじめていきましょう。

この記事でわかること
クローラビリティとは?
クローラビリティは、検索エンジンがサイト構造を理解しながら必要なページへ効率よく到達できるかを表す考え方です。
単に「クローラーが来るかどうか」だけではなく、どのURLを優先して見つけられるか、リンクをたどって重要ページに到達しやすいか、レンダリング後の内容まで把握しやすいかまで含みます。
たとえば、カテゴリと記事の関係が整理され、パンくずリストや内部リンクが機能し、不要な重複URLが抑えられているサイトは、クローラビリティが高い状態です。反対に、リンク切れが多い、絞り込みURLが大量に増えている、JavaScriptでしか主要リンクが出てこない、といったサイトはクローラビリティが下がりやすくなります。
検索エンジンはページを発見し、取得し、内容を理解してから評価に進みます。その入口でつまずかないための土台が、クローラビリティです。
クローリングとインデックス
検索結果に表示されるには、まずクロールされ、その後にインデックスされる必要があります。
クローリングとは、検索エンジンのクローラーがURLを発見し、ページへアクセスして内容を取得する工程です。その後、取得した情報を解析し、検索結果の候補としてデータベースに保存する工程がインデックスです。
つまり、インデックスの前提としてクロールがあります。ただし、クロールされたからといって必ずインデックスされるわけではありません。内容の重複、品質、正規化の問題、noindex設定などがあると、クロール後にインデックスされないこともあります。
SEOの現場では、この2つを混同すると原因を見誤りやすくなります。ページが検索結果に出ないとき、問題が「見つけてもらえていない」のか、「見つかっているが採用されていない」のかで打ち手は変わるためです。まずはクローリングとインデックスを分けて考えることが大切です。
⇒インデックスの詳細は、インデックスとは?確認方法や登録方法、SEOへの影響で詳しく解説しています。
SEOにおけるクローラビリティの重要性
クローラビリティが重要なのは、検索エンジンに評価してほしいページへ、限られたクロール機会を正しく使ってもらうためです。
検索エンジンは、サイト内のすべてのURLを同じ優先度で見るわけではありません。Googleはサイトの応答状況やURL群の重要度、更新頻度などを踏まえてクロール頻度や対象を調整しています。特に大規模サイトや更新頻度の高いサイトでは、不要URLが多いだけで重要ページの再クロールが遅れやすくなります。参照:クロール バジェットの管理
クローラビリティが高いサイトでは、新規公開ページや更新ページが見つかりやすく、構造も理解されやすくなります。その結果、評価の起点に立ちやすくなります。逆に、重要でないURLにクロールが分散すると、肝心のページの発見や更新反映が遅れます。
また、クローラビリティはテクニカルSEOだけの話ではありません。ユーザーが迷わない導線は、クローラーにとっても理解しやすい導線であることが多いためです。パンくず、カテゴリ設計、関連ページへの自然な内部リンクは、ユーザー体験とクロール効率の両方に効きます。
当社でもSEO改善の相談を受ける際、最初に確認するのは「記事の質」などのコンテンツ面ではなく、クロールとインデックスの状況です。この土台ができていないとコンテンツ側に如何に力を入れても十分な評価を受けられないからです。
クローラビリティを改善・向上させる11つの方法
クローラビリティ改善で優先すべきなのは、重要URLを見つけやすくし、不要URLへのクロール浪費を減らすことです。
ここでは、現場で再現しやすい11の方法を順番に解説します。すべてを一度に行う必要はありませんが、インデックスされにくい、更新が反映されにくい、検出-インデックス未登録が多いといった状態なら、上から順に確認していくと原因を切り分けやすくなります。
サーチコンソールからクローリングをリクエストする
新規公開や大きな更新をしたページは、Google Search ConsoleのURL検査から再クロールを促すのが基本です。
やることはシンプルで、Google Search Consoleの上部検索窓に対象URLを入力し、状態を確認したうえで「インデックス登録をリクエスト」を実行します。これにより、そのURLを見てほしいというシグナルを送れます。
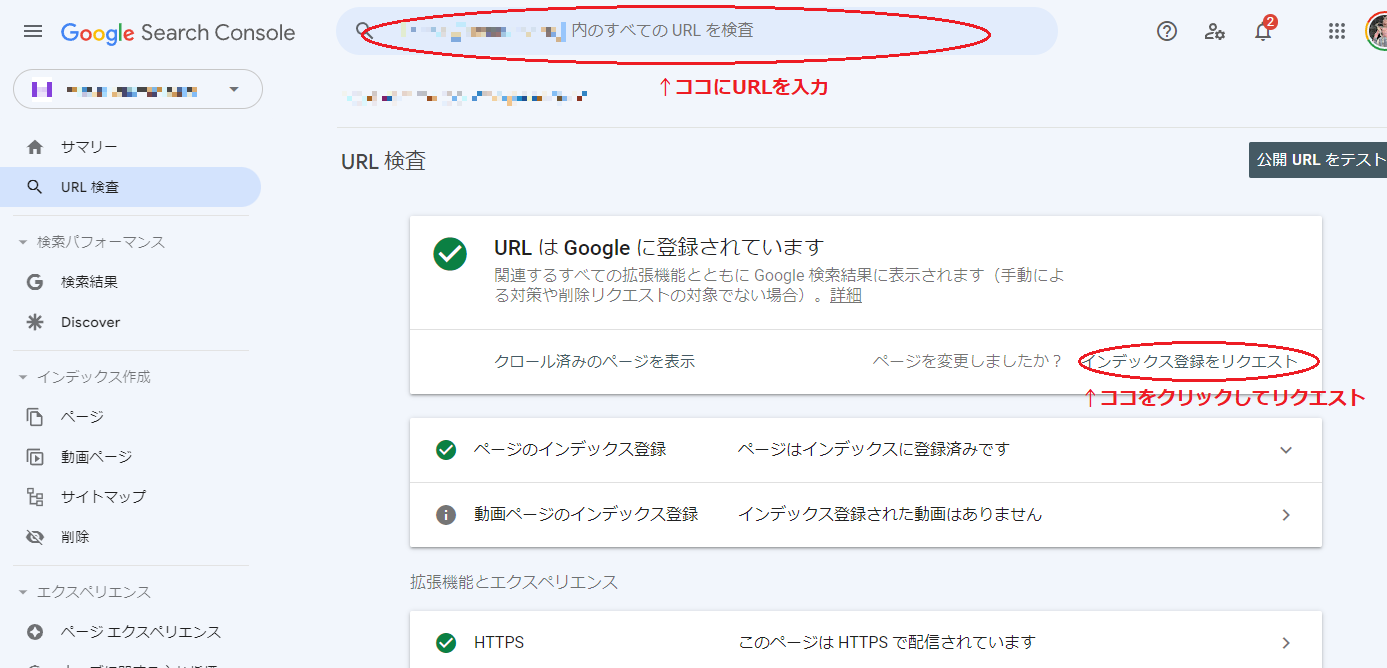

ただし、これは即時反映の保証ではありません。Googleは多くのサイトを順次処理しているため、リクエスト後もしばらく時間がかかることがあります。特に2026年時点でも、一般的なサイトでは公開当日のクロールやインデックスを前提にしないほうが安全です。
この施策が有効なのは、重要ページを個別に知らせられるからです。たとえば、サービスページを全面改訂した、比較表を更新した、古い情報を2026年版に直した、といった場面では優先度が高い対応です。
⇒設定や使い方を詳しく理解したい場合は、Googleサーチコンソールとは?機能や設定方法、使い方などを初心者にわかりやすく解説も是非参照ください。
XMLサイトマップを送信・更新する

XMLサイトマップは、重要URLを検索エンジンに伝えるための基本施策です。
サイトマップがあると、検索エンジンはサイト内の重要ページを把握しやすくなります。特に、内部リンクだけでは見つかりにくいページ、更新頻度が高いページ、画像や動画を含むページでは効果を感じやすい施策です。Googleも、サイトマップは重要ページや更新情報を伝える大切な手段だと案内しています。参照:ウェブサイトのSEOの管理
作成方法はCMSによって異なりますが、WordPressならSEOプラグインや標準機能で自動生成できることが多く、手動でゼロから作る必要はあまりありません。大切なのは、インデックスさせたいURLだけを含めることです。noindexページ、重複ページ、検索結果ページ、絞り込みだけのURLまで入れると、かえって優先順位がぼやけます。
また、更新のたびにサイトマップが自動更新される設計にしておくと運用が安定します。記事を追加したのにサイトマップに反映されていない、削除したURLが残っている、といった状態は避けたいところです。
公開本数が増えてきたサイトほど、サイトマップの品質差がじわじわ効いてくるものです。数ページ規模では目立たなくても、数千URLを超えると「何を優先して見てほしいか」を明示できているサイトのほうが、更新反映の安定感が出やすいためです。
⇒XMLサイトマップの詳細は、XMLサイトマップ(sitemap.xml)とは?SEO効果や作成、設置方法については、あわせてご覧ください。
パンくずリストを設置する
パンくずリストは、ページの階層関係をクローラーとユーザーの両方に伝えやすくする施策です。
たとえば「ホーム > SEO > テクニカルSEO > クローラビリティ」のように、現在地と上位カテゴリを示すことで、ページ同士の関係が明確になります。クローラーはリンクをたどって構造を把握するため、パンくずがあるとサイト全体の整理された構造を理解しやすくなります。
ユーザー面でも、今どこを見ているのかが分かりやすく、上位カテゴリへ戻りやすくなります。結果として回遊が改善し、重要カテゴリページにもリンクが集まりやすくなります。
実装時は、見た目だけのテキストではなく、実際にクリックできるリンクとして設置することが重要です。カテゴリ名が曖昧だったり、途中階層が省略されていたりすると、構造理解の助けになりにくくなります。
⇒パンくずリストの考え方は、パンくずリストとは?種類やSEO効果、実装方法で整理しています。
内部リンクを設置する
重要ページへ内部リンクを集めると、クローラーがそのページを発見しやすくなり、サイト内の優先度も伝えやすくなります。
内部リンクは、関連記事をつなぐだけの装飾ではありません。カテゴリページから詳細ページへ、比較記事からサービスページへ、基礎記事から応用記事へと、意味のある導線を作ることで、クローラーはページ同士の関係を理解しやすくなります。
ポイントは、リンク先と文脈を一致させることです。「詳しくはこちら」だけではなく、「canonicalタグの設定方法」「ECサイトの絞り込みURL対策」のように、リンク先の内容が分かるアンカーテキストにすると、ユーザーにもクローラーにも親切です。
一方で、無差別にリンクを増やすのは逆効果です。本文の流れに関係ないリンクが多いと、重要導線が埋もれます。古い記事が孤立している、関連記事が自動表示任せで重要ページに評価が集まらない、といった状態は見直し余地があります。
⇒内部リンクの詳細は、内部リンクとは?SEOの効果や正しい貼り方、おすすめのリンク設置場所で詳しく解説しています。
robots.txtでクロールを拒否する
robots.txtは、クロールしてほしくないURL群を制御するために使いますが、インデックス制御の代替にはなりません。
たとえば、サイト内検索結果ページ、並び替えURL、絞り込みだけで内容差がほぼないURL、カート投入や会員登録など状態が変わるURLは、robots.txtでクロール対象から外す判断が有効なことがあります。大規模サイトでは、こうした不要URLを放置するだけでクロール効率が落ちやすくなります。
ただし、検索結果に出したくないURLをrobots.txtだけで制御しようとしないことが重要です。Googleは、表示や登録に関するルールを適用する必要があるURLは、クロールできなければその指示を確認できません。つまり、noindexを効かせたいURLをrobots.txtで塞ぐのは不適切です。参照:robots メタタグ、data-nosnippet、X-Robots-Tag の仕様
現場でよくあるのは、「とりあえずrobots.txtで止める」運用です。しかし、これで重要CSSやJavaScriptまでブロックしてしまうと、レンダリング後の内容理解に支障が出ることがあります。制御対象は、あくまで重要でないURL群に絞るのが安全です。
⇒robots.txtの設定方法は、robots.txtとは?意味や設定方法を正しく学び、SEO効果を高めようも参考にしてみてください。
URLを正規化する
同じ内容に近いページが複数URLで存在するなら、canonicalやリダイレクトで正規URLを明確にすることが重要です。
URLの正規化が必要になるのは、たとえば以下のような場面です。
- ECで色違い・サイズ違いの商品ページが多数あり、説明文がほぼ同じ状態
- 並び替えや絞り込みでURLだけが増え、内容差が小さい一覧ページが量産されている状態
- 末尾スラッシュあり・なし、http/https、wwwあり・なしが混在している状態
- 広告計測パラメータ付きURLが別ページのように扱われている状態
このような状態では、クローラーが似たURLを何度も見に行き、重要ページへのクロールが薄まりやすくなります。canonicalで代表URLを示し、必要に応じて301リダイレクトで統一すると、評価の分散も抑えやすくなります。
私もサイト診断の際、順位が伸びない原因として「コンテンツ不足」より先に、評価してほしいURLが曖昧なケースをよく見ます。特にCMS移行後やECの機能追加後は、意図せず重複URLが増えやすいため注意しましょう。
シンプルなURLにする
URLは短く、意味が分かり、階層が読み取りやすい形にすると、クローラーにもユーザーにも伝わりやすくなります。
理想は、URLを見ただけでページ内容をある程度推測できることです。たとえば、/seo/crawlability/ のようなURLは分かりやすい一方、/2/6772756D707920636174 のような識別子中心のURLは内容が伝わりません。
また、単語区切りにはハイフンを使い、不要な記号や長すぎるパラメータは避けるのが基本です。日本語URL自体が直ちに問題になるわけではありませんが、共有や管理のしやすさまで考えると、英数字ベースで簡潔に設計するほうが運用しやすいことが多いかと思います。
シンプルなURLは、後から大規模修正しにくい要素です。新規ディレクトリを作る段階でルールを決めておくと、将来のリダイレクトや重複管理の作業負荷を抑えやすくなります。
ディレクトリの階層を浅くする
重要ページが深い階層に埋もれていると、発見も回遊も遅くなりやすいため、構造はできるだけ浅く保つのがおすすめです。
ここでいう「浅い」とは、URLの文字数だけではなく、トップや主要カテゴリから何クリックで到達できるかも含みます。たとえば、トップ > カテゴリ > 記事 のように整理されていれば、クローラーもユーザーも辿りやすくなります。
一方で、カテゴリの下にサブカテゴリが何層も続き、その先に個別記事がある構造だと、重要ページが埋もれやすくなります。特に、古い記事がアーカイブの奥に沈み、内部リンクも少ない状態は改善余地が大きいです。
「3クリック以内」は絶対ルールではありませんが、重要ページが深くなりすぎない目安としては有効です。BtoBのサービスサイトでも、料金、導入事例、比較、FAQなどの重要ページは浅い位置に置くほうがクロールも回遊も安定しやすくなります。
ファイルサイズを減らす
ページやリソースが重すぎると、取得やレンダリングに時間がかかり、クロール効率を落とす要因になります。
特に見直したいのは、画像、JavaScript、CSSです。高解像度画像をそのまま掲載している、使っていないスクリプトが多い、CSSが肥大化しているといった状態では、ページ表示だけでなくクローラーの処理負荷も上がります。
対策としては、画像の圧縮と次世代フォーマットの活用、JavaScriptやCSSの圧縮、不要コードの削除、キャッシュ設定の見直しなどが基本です。装飾画像や意味理解に不要な重いリソースは、必要に応じてクロール対象から外す判断もあります。
Googleはレンダリング時にJavaScriptも実行するため、HTMLだけ軽ければ十分というわけではありません。見た目は表示されていても、レンダリング完了までに時間がかかるページは、クロール面でも不利になりやすい点に注意しましょう。
サーバーを最適化する
サーバー応答が遅い、または5xxエラーが多い状態は、クロール頻度の低下につながるため、可用性の改善は優先度が高い施策です。
Googleはサイトに負荷をかけすぎないよう、応答状況を見ながらクロール速度を調整します。サーバーエラーや遅延が続くと、「このサイトは無理に取りに行かないほうがよい」と判断され、クロールが抑制されることがあります。
確認したいのは、平均応答時間、5xxエラーの有無、タイムアウト、急なアクセス増加時の安定性です。Search Consoleのクロール統計情報やサーバーログを見ると、Googlebotがどの時間帯に失敗しているかを把握しやすくなります。
当社でもメディア運用の改善では、記事追加より先にホストの安定性を確認することがあります。公開本数が増えているのに更新反映が遅い場合、原因がコンテンツではなくサーバー負荷やキャッシュ設定にあることがあるためです。
被リンクを獲得する
被リンクは評価シグナルとしてだけでなく、新しいURLの発見経路としてもクローラビリティに関わります。
検索エンジンはリンクをたどって新しいページを見つけます。そのため、外部サイトから自然なリンクが張られると、発見のきっかけが増えます。特に新規ドメインや公開直後のコンテンツでは、内部リンクだけより見つけてもらいやすくなることがあります。
有効なのは、引用されやすい一次情報を出すことです。たとえば、自社調査データ、独自アンケート、導入事例、業界比較表、実務テンプレートなどは紹介されやすくなります。2026年時点では、AI生成の一般論だけでは差別化しにくいため、こうした一次情報の価値が相対的に高まっています。
SEO対策で被リンクが勝手に集まることは滅多にないので、良いコンテンツを作ったら、X(旧Twitter)やメールマガジン、プレスリリース、業界コミュニティなどで発信し、紹介されるきっかけを増やすことが重要です。待つだけより、見つけてもらう導線まで設計するのがおすすめです。
クローリングされているかを確認する方法
クローラビリティ改善は、施策を打って終わりではなく、実際にクロール状況を確認して初めて意味があります。
ここでは、現場で使いやすい3つの確認方法を紹介します。結論から言うと、最も信頼しやすいのはGoogle Search Consoleで、site:検索は補助的な確認、cache:検索は現在は主手段にしない、という整理で考えるのが安全です。
Googleサーチコンソールで確認
個別URLの状態確認は、Google Search ConsoleのURL検査が最も確実です。
確認したいURLを検索窓に入力すると、そのURLがGoogleに登録されているか、最後にクロールされた時期、正規URLの扱い、モバイルでの取得状況などを確認できます。

「URLはGoogleに登録されています」と出れば、少なくともインデックス候補として扱われています。一方で、検出済みだが未クロール、クロール済みだが未登録、といった表示なら、問題は発見段階なのか品質・重複段階なのかを切り分けられます。
また、サイト全体を見るなら「ページ」レポートや「クロール統計情報」も有効です。特定ディレクトリだけ未登録が多い、5xxが増えている、HTML以外の取得が多すぎる、といった傾向が見えてきます。
「site:URL」で検索
site:検索は、インデックスされているかをざっくり確認する補助手段として使えます。
使い方は簡単で、Google検索窓に site:example.com と入れると、そのドメイン配下で表示されるページを確認できます。特定ページだけ見たいなら、site:example.com/service/seo/ や完全URLに近い形で絞り込む方法もあります。
ただし、site:検索の件数表示は正確なインデックス総数ではありません。表示順も通常検索とは異なり、すべての登録URLが漏れなく出るわけでもありません。そのため、「出ていないから未登録」と即断するのではなく、気になるURLはSearch Consoleで再確認することが大切です。
それでも、カテゴリ単位で露出状況をざっと見るには便利です。たとえば、ブログ記事は出るのにサービスページだけほとんど出ない場合、内部リンクやnoindex、canonicalの設定を疑うきっかけになります。
「cache:URL」で検索
cache:検索は以前よく使われた方法ですが、2026年時点では確認手段としての優先度は高くありません。
過去には、Googleが保持するキャッシュ表示から最終クロール時点のスナップショットを確認できましたが、現在は安定して使える方法ではなく、表示されないことも珍しくありません。そのため、cache:が出ないことだけで未クロールと判断するのは危険です。
もし確認するなら補助的に使い、主判断はSearch ConsoleのURL検査に置くのがよいでしょう。特に、noindex、canonical、レンダリング差分、モバイル取得状況などはcache:では十分に追えません。
よくある質問
クローラビリティとインデックス率は同じ意味ですか?
いいえ、同じではありません。クローラビリティはクローラーがページを見つけて巡回しやすいかという土台の話で、インデックス率はその結果としてどれだけ検索エンジンに登録されたかを示す状態です。クローラビリティが高くても、重複や品質の問題でインデックスされないことはあります。
小規模サイトでもクローラビリティ改善は必要ですか?
必要です。大規模サイトほど影響が大きいのは確かですが、小規模サイトでも内部リンク不足、noindexの誤設定、重複URL、サーバー不安定などで重要ページが見つかりにくくなることがあります。特に新規サイトは発見経路が少ないため、基本整備の効果が出やすいです。
robots.txtでブロックすれば検索結果にも出なくなりますか?
必ずしもそうではありません。robots.txtはクロール制御のための仕組みで、インデックスを確実に防ぐ手段ではありません。検索結果から除外したい場合は、noindexや認証制御など、目的に合った方法を使う必要があります。
JavaScriptを使ったサイトはクローラビリティが悪くなりますか?
JavaScriptを使っているだけで問題になるわけではありません。ただし、主要コンテンツやリンクがレンダリング後にしか出てこない、重要リソースがブロックされている、描画が重いといった状態では、クロールと理解が遅れやすくなります。HTML初期表示とレンダリング後の差分は確認したほうが安全です。
クローラビリティ改善の効果はどれくらいで分かりますか?
サイト規模や問題の種類によりますが、数日で変化が見えることもあれば、数週間から数か月かかることもあります。特にSEOでは、公開直後に一時的に順位が付き、その後に上下を繰り返して落ち着くGoogleハネムーンのような動きもあるため、短期の順位だけで判断しないことが大切です。クロール頻度、インデックス状況、重要ページの再取得状況をあわせて見ましょう。
まとめ
クローラビリティは、良質なコンテンツを正しく評価してもらう前提となる重要な土台であり、特に大規模サイトやURLが増えやすいサイトでは、クロール効率の差が検索流入にも影響しやすくなります。
コンテンツ側の施策やリンクの施策に移る前に一番最初にしっかり整備しておきましょう。
