
クローラー(Crawler)は、検索エンジンがWebサイトの情報を収集するため、インターネット上を巡回させているロボット(bot)です。
検索エンジンは、クローラーが集めてきた情報をデータベースにインデックスし、アルゴリズムに基づいて検索順位を決定します。そのため、SEO対策の第一歩としてクローラーを自社サイトに導き、Webサイト内を回遊しやすい状況に整えておく必要があります。
このページでは、クローラーの種類や検索エンジンの仕組み、どうすれば自社サイトを見つけてもらいやすくなるか解説します。
クローラーに効率良く自社サイトの情報を集めてもらい、作成したコンテンツをいち早くユーザーに見てもらえる環境を整えましょう。

この記事でわかること
クローラーとは
クローラーとは、グーグルやヤフーなどの検索エンジンが、インターネット上にある数多のWebサイトの情報を集めるため、巡回させているロボット(bot)です。
SEO対策には、コンテンツ作成や内部施策、外部施策などさまざまな種類がありますが、クローラーがWebサイトを訪れ、情報を得られなければ、検索エンジンの検索結果に表示されることもありません。
そもそも、検索エンジンはどのような仕組みで検索結果に表示させるWebページを見つけているのでしょうか、次に解説します。
検索エンジンの仕組み
グーグルやヤフーを利用し、知らない情報について調べてみると、求めている情報が掲載されたWebページが当たり前のように表示されます。
検索結果が表示されるまで、検索エンジンはどのような仕組みで動いているのか、クローラーの動きに沿ってご紹介します。
- 検索エンジンからインターネット上にクローラーが流される
- インターネット上にあるリンクを辿り、Webサイトを訪問する
- Webサイトにある情報を集める
- 収集した情報を検索エンジンに持ち帰り、データベースに登録(インデックス)する
- ユーザーが検索する際に、インデックス内のデータをアルゴリズムに基づいて評価する
- 検索意図に最も近くの高いWebページから順に上位表示させる
つまり、クローラーが自社サイトに回ってこなければ、新しい情報は検索エンジンのデータベースにインデックスされません。インデックスされなければ、Webサイトやページが評価されることも、検索結果画面に表示されることがないのです。
新しいコンテンツの作成、既存コンテンツの情報更新をしたら、クローラーを自社サイトに呼び込み、それぞれの情報を収集してもらい、検索エンジンのデータベースにインデックスしてもらいましょう。
続いて、クローラーにはどのような種類があるのか、またWebサイト内でどのような情報を収集するのか、解説します。
クローラーの種類とWebページで収集する情報について
検索エンジンのクローラーには、主に以下の5つが挙げられます。
- GoogleのクローラーであるGooglebot
- Yahoo!のクローラーであるYahoo Slurp
- BingのクローラーであるBingbot
- Baidu(中国)のクローラーであるBaiduspider
- Naver(韓国)のクローラーであるYetibot
これらのクローラーは、検索エンジンのデータベースにある情報内のリンクを辿って、インターネット上で巡回を始めます。
Webサイトに到着後は、内部リンクやXMLサイトマップ、パンくずリストなどから各ページに入り、以下の情報を集めます。
- テキスト
- HTMLタグ
- CSS
- 画像・動画
- php・JavaScript
Webページは、クローラーが集めたこれらの情報が検索エンジンのデータベースにインデックスされ、アルゴリズムによって評価された上で、はじめて検索エンジンの「検索結果画面」に表示されるのです。
次に、どうすればクローラーが自社サイトに訪問してくれるようになるのか、その方法をご紹介します。
クローラーが検索しやすいWebサイトを目指す7つの施策
新しいコンテンツやWebサイト内で更新したWebページへ、クローラーを導くにはどのような対策が必要なのでしょうか。
クローラーに見つけてもらいやすいWebサイト作りを目指すことは「クローラビリティの向上」と呼ばれ、SEO対策でも重要な施策の1つです。
具体的にはどのようなことを行うべきなのか、以下、ご紹介します。
内部リンクの最適化を行いWebサイト内をクローラーが回りやすくする
1つ目は、内部リンクの設置と最適化です。
クローラーは、自社サイト内のリンク(内部リンク)や他社Webサイトからのリンク(被リンク)を頼りに、各コンテンツを巡回する仕組みを持ちます。
被リンクは、自社ではコントロールできませんが、内部リンクに関しては、自社でコントロール可能です。 そのため、内部リンクを正しく設置し最適化することで、クローラビリティが向上します。
しかし、だからといって、無闇やたらに内部リンクを設置することは、かえってクローラビリティを下げることにも繋がります。 内部リンクを適切に設置する方法として、以下の点に注意しましょう。
- 関係性のあるページ同士を結びつける
- アンカーテキストはリンク先の情報が分かりやすいものにする
- 3クリック以内で全てのページへたどり着けるようにする
内部リンクに関する詳しい情報、最適化のコツは『内部リンクとは?最適化が与えるSEO効果や失敗しない貼り方、設置場所を解説』で解説しているので、ご一読ください。
URLを正規化しコンテンツをまとめる
2つ目のクローラビリティ改善に向けた施策は、URLの正規化です。
Webサイトの中にはシステムやサーバーなどの影響で、以下のようなURLは異なるものの内容が同じコンテンツが複数存在してしまう場合があります。このような場合に、「URLの正規化」を行うことで、分散するSEO評価を1つのURLへまとめることができ、効率よくクローリングしてもらうことが可能です。
- www.の有無(https://www.aaa.co.jp と https://aaa.co.jp)
- /index.htmlの有無(https://aaa.co.jp と https://aaa.co.jp/index.html)
- /の有無(https://aaa.co.jp と https://aaa.co.jp/)
- 計測のためのパラメーター(https://aaa.co.jp と https://aaa.co.jp/?utm~)
- SSL設定(http://aaa.co.jp と https://aaa.co.jp)
上記は、いずれもWebサイトのトップページに該当するURLですが、URLの表記が異なる場合、クローラーはそれぞれを別々のページと認識し情報を集めてしまいます。
もし、別々のページと認識されてしまうと、それぞれのページが評価され、評価の分散が起きてしまいます。また、クローラーにはクローリングするぺージ数に限界値(クローラーバジェット)を持っているため、その他のコンテンツが正しくクローリングされないなどに繋がります。
評価の分散やクローラーバジェットの浪費を防ぐためにも、canonicalタグを使ってURLの正規化を行い、指定した1つのURLをクロールさせましょう。
canonicalタグを使ったURLの正規化については『canonical(カノニカル)とは?URLの正規化でSEO対策を進めよう』に詳しくまとめていますので、ぜひ、ご参照ください。
XMLサイトマップの作成と設置
3つ目は、XMLWebサイトマップの作成と設置です。
XMLサイトマップは、Webサイト内のどこに、どのようなコンテンツがあるかをクローラーに知らせる地図のようなものです。
XMLサイトマップを作成しサーバーにアップロードすることで、クローラビリティの向上に役立ちます。 というのも、Webサイト内のページの中には、内部リンクが貼られておらず、クローラーが自力で発見しにくいものがあります。また、内部リンクが設置されているものの、該当のページへ辿り着くまでに複数回のリンクをクリックしなければ、到達できない記事もクローラーは発見しにくいです。
そのような記事をクローラーに巡回してもらうためにも、XMLサイトマップの作成と設定が必要です。Webサイトの規模が大きくなり、ページ数が増えているものの、まだXMLサイトマップを設定していないのであれば、導入することをおすすめします。
XMLサイトマップの作成、設定方法は『XMLサイトマップ(sitemap.xml)とは?SEO効果や作成、設置方法を解説』でご確認いただけます。お役立てください。
パンくずリストを設定する
4つ目は、パンくずリストの設定です。
パンくずリストとは、ユーザーがWebサイトの構造内でどこにいるかを示すナビゲーションで、基本的にはページ上部に設置されています。
ユーザーは、パンくずリストを確認することで、求める情報が記載された別ページへ移動しやすくなります。
また、パンくずリストがあることでクローラーにとってもWebサイトの構造を理解しやすくなり、クローラビリティの向上につながるというメリットをもたらします。
パンくずリストは内部リンクにも該当するため、まだ導入できていない場合には、パンくずリストを設定することをおすすめします。 パンくずリストの種類や設定方法は『パンくずリストとは?種類やSEO効果、実装方法を徹底解説』にまとめているのでご参照ください。
外部Webサイトからの被リンク
5つ目は、外部サイトに貼ってもらったリンク(被リンク)から、自社サイトを巡回してもらう方法です。
クローラーは、リンクを頼りにWebサイトを巡回しているため、外部サイトから自社サイトへのリンクが貼られていれば、クローラーの入り口になります。
外部サイトからの被リンクは、自社サイトの評価が上がるため、SEO効果にもつながります。 ただし、検索エンジンが評価する被リンクは、「自社サイトで案内している内容と結びつきがあり、コンテンツの質が高い外部Webサイトからのリンク」に限られます。
自社サイトと関係がなく、内容の薄い低品質なコンテンツばかりの外部サイトからの被リンクは、自社サイトの評価を下げることにつながるので注意しましょう。
被リンクについては『被リンクのSEO効果とは?対策と獲得方法を徹底解説』にて詳しく解説しています。
robots.txtを設置して不要なページへのクロールを制限
6つ目は、robots.txtを利用してクローラーに不要なページへのアクセスを制限する方法です。
先にご紹介した通り、クローラーがWebサイト内を巡回する場合、全てのページを巡回できるわけではなく、ぺージ数に限界値(クローラーバジェット)があるため、その動きには上限があります。
クローラーを検索エンジンのデータベースにインデックスさせる必要のないページに巡回させないようアクセスを制限することで、より効率よくWebサイト内の収集してもらいたい情報を集めてもらえます。
例えば、自社サイト内の問い合わせフォームや、その後に表示されるサンクスページはユーザーに確認してもらうため必要ではあるものの、内容は薄くインデックスしてもらう必要はありません。
robots.txtとは、Webサイト内でクローラーを上記のような不要なページへアクセスしないよう制限するためのテキストファイルです。
会員登録ページや、新しいシステムを導入するためテストページを作成している場合など、インデックスを避けたいページがあれば、robots.txtファイルを使い、クローラーを巡回させない設定をしておきましょう。
robots.txtでクローラーのアクセスを制限し、ユーザーの役に立たない低品質なページをインデックスさせないことは、SEO対策にもなります。 robots.txtの設定方法については『robots.txtとは?意味や設定方法を正しく学びSEO効果を高めよう』で詳しく解説しています。ご参照ください。
Google Search Consoleからクロールをリクエスト
最後に、クローラーを呼び込むためのリクエストを行う方法をご紹介します。
新しいコンテンツを作って公開、または時間経過による情報変化に合わせてコンテンツ内容を更新したら、無料で利用できるSEOツールであるGoogle Search Console(サーチコンソール)を使い、クローラーを呼ぶためのリクエストをしましょう。
Google Search Consoleにログインしたら、メニューの中から「検索パフォーマンス」を選び、検索窓(PC画面なら画面上部、スマートフォンやタブレットの場合は画面上部の虫眼鏡をクリック)に、クロールさせたいページのURLを入力します。
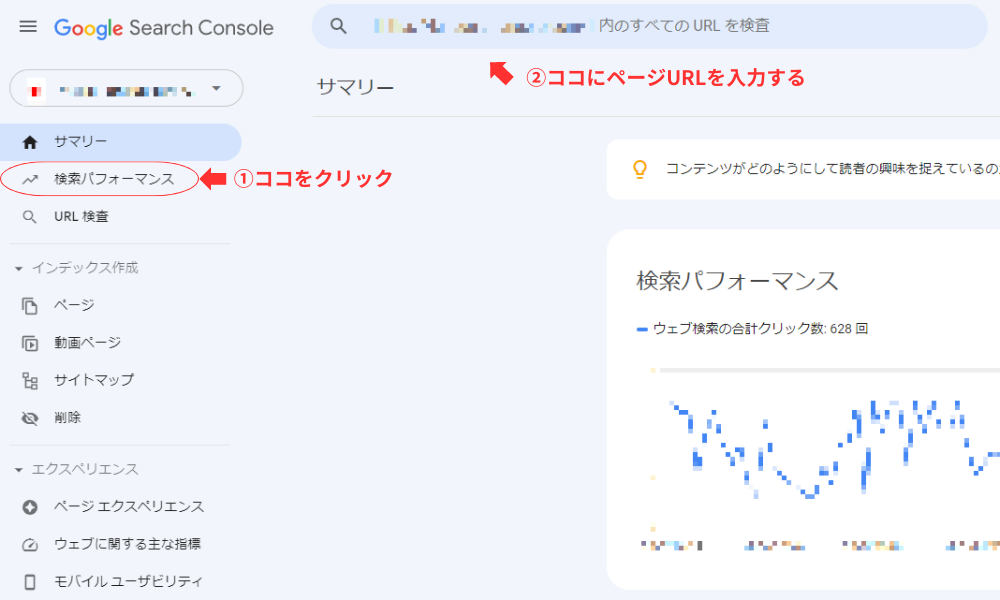
新規ページの場合は「URLがGoogleに登録されていません」と表示され、既存ページだと「URLはGoogleに登録されています」と表示されます。いずれの場合も、その下にある「インデックス登録をリクエスト」をクリックすれば、該当ぺージのクローリングをリクエストできます。
クローラビリティ向上に有効な施策を解説したところで、次に、ページがインデックスされたかどうか、確認する方法をご紹介します。
クローラーがページを巡回しインデックスされたか確認する3つの方法
クローラーが自社サイトを巡回した後は、検索エンジンのデータベースにインデックスされたか確認しておきましょう。
インデックスを確認する3つの方法をご紹介します。
Google Search Consoleでインデックスの確認
1つ目は、Google Search Consoleを使った確認方法です。
ログイン後、PC画面なら上部の空欄、スマートフォンやタブレットの場合は虫眼鏡をタップして検索窓を開き、確認したいページのURLを入力します。インデックスされていれば、「URLはGoogleに登録されています」と表示されます。
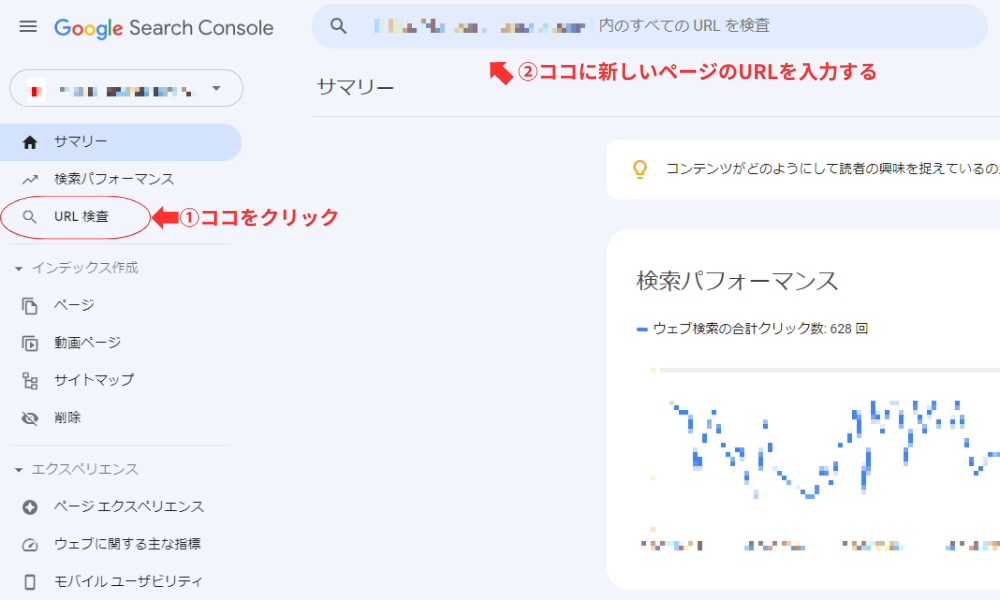
「URLがGoogleに登録されていません」と表示される場合は、まだインデックスが完了していません。インデックスには時間がかかる場合もあります。
数日様子を見て、インデックスされていない場合は、noindexタグが誤って設定されていないか、robots.txtファイルに該当ページのクロール拒否を記載していないか確認し、再度クローリングをリクエストしましょう。
site:URLで検索する
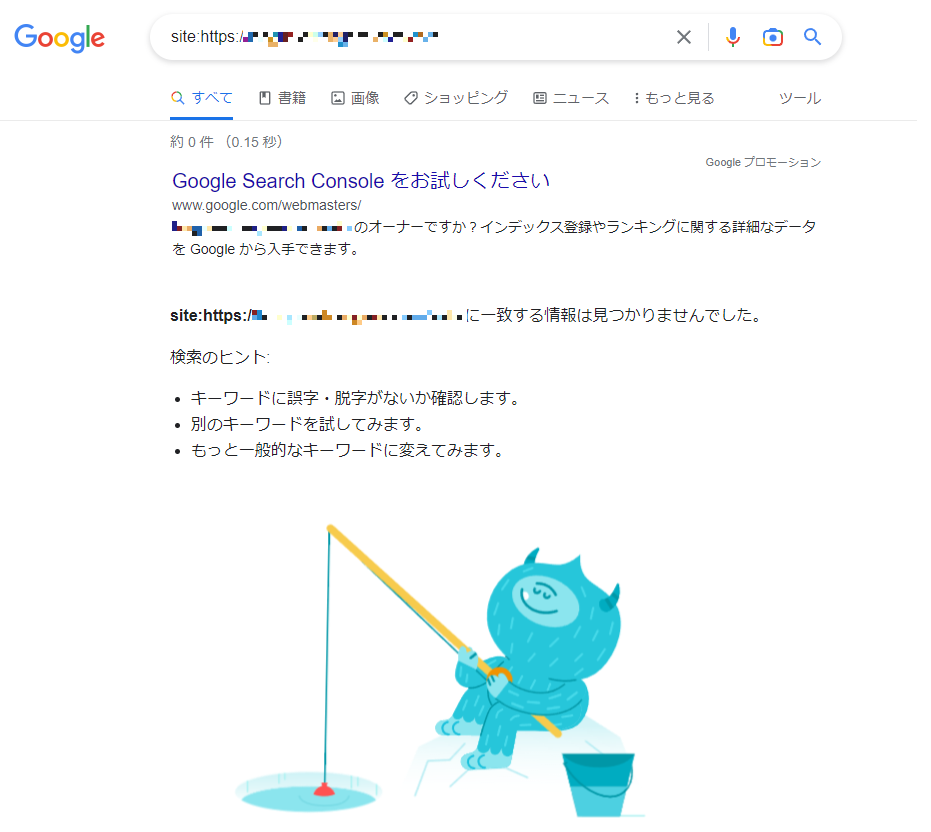
2つ目のインデックス確認方法は、site:URLでの検索です。
Googleの検索窓に、「site:(コロン)」+URLを入力し、検索をかけます。インデックスされていれば、検索結果として該当ページのタイトルと概要が表示されます。
cache:URLで検索する
3つ目の方法は、cache:URLでの検索です。
「cache:(コロン)」+URLでGoogle検索をかけると、Google が最後にアクセスしたときのウェブページの状態を、キャッシュ情報を元に表示させます。
新規ページであれば、表示された時点ですでにインデックスされたことを意味します。既存ページの情報更新を行い、クローラーが新しい情報を読み込んだかどうか確認する場合は、該当ページを開いて変更部分をチェックしておきましょう。
まとめ
クローラーとは何かを理解すると、効率的なSEO対策を進められます。
自社サイトをスタートさせたばかりで新しいコンテンツを作り続けているものの、なかなかインデックスされず検索結果画面に表示されない場合は、自社サイトがクローラーの巡回しやすい状態になっているか、確認しましょう。
すでにWebサイトを立ち上げてから時間が経過し、規模が大きくページ数も増えている状態なら、クローラビリティを改善するとクローラーが自社サイトに訪れる頻度を上げることができ、SEO効果も大きくなります。
このページで紹介した施策を取り入れ、ユーザーだけでなく、クローラーにとっても快適なWebサイト運営を心がけましょう。クローラビリティの改善方法については以下のページで詳しく解説していますので、お役立てください。

